
- 行业动态 >
- 资讯详情
小(xiǎo)数据治理(lǐ)靠“人工”,大数据治理(lǐ)靠“智能(néng)”
 2020/03/05
2020/03/05
 2536
文(wén)章来源:数据工匠俱乐部 原作者:石秀峰
2536
文(wén)章来源:数据工匠俱乐部 原作者:石秀峰



一、什么是小(xiǎo)数据治理(lǐ)
谈小(xiǎo)数据治理(lǐ),首先说一说什么是小(xiǎo)数据。在百度百科(kē)上我们可(kě)以查到小(xiǎo)数据的定义是:“小(xiǎo)数据(small data),或称个體(tǐ)资料,是指需要新(xīn)的应用(yòng)方式才能(néng)體(tǐ)现出具有(yǒu)高价值的个體(tǐ)的、高效率的、个性化的信息资产。”小(xiǎo)数据,并不是指数据量小(xiǎo),而是围绕个人為(wèi)中心全方位的数据,及其配套的收集、处理(lǐ)、分(fēn)析和对外交互。在筆(bǐ)者看来,小(xiǎo)数据是相对大数据而言的,在大数据的概念没有(yǒu)出现之前,数据就是数据,没有(yǒu)什么大小(xiǎo)之分(fēn),但由于应用(yòng)场合、存储方式、处理(lǐ)方式的不同却分(fēn)出大小(xiǎo),就有(yǒu)了所谓的大数据、小(xiǎo)数据。从广义上来讲,大数据通常指的是大量结构化数据与非结构化数据的集合體(tǐ),而小(xiǎo)数据通常指的是结构化数据。
小(xiǎo)数据治理(lǐ)范围包括:主数据管理(lǐ)、数据标准管理(lǐ)、数据质量管理(lǐ)、元数据管理(lǐ)。小(xiǎo)数据的治理(lǐ)讲求的是:有(yǒu)序、量化、精准,小(xiǎo)数据的一切工作都是围绕这个目标而开展的。而在小(xiǎo)数据治理(lǐ)领域,主数据管理(lǐ)的应用(yòng)十分(fēn)典型。虽然说小(xiǎo)数据不等于是主数据,但主数据却是一种典型的小(xiǎo)数据。主数据治理(lǐ)在小(xiǎo)数据治理(lǐ)领域是具备一定的代表性的,完全符合小(xiǎo)数据治理(lǐ)的“有(yǒu)序、量化、精准”三大目标。
二、什么是大数据治理(lǐ)
对于“大数据”我们都知道他(tā)的4V特点:Volume(大量)、Velocity(高速)、Variety(多(duō)样)、Value(低价值密度)。由于这“4V”特点的存在,导致大数据的处理(lǐ)和利用(yòng)模式,与传统的结构化数据不同。正如研究机构Gartner给出的定义:“大数据”是需要新(xīn)处理(lǐ)模式才能(néng)具有(yǒu)更强的决策力、洞察发现力和流程优化能(néng)力来适应海量、高增長(cháng)率和多(duō)样化的信息资产。
大数据治理(lǐ)从概念上来说与数据治理(lǐ)没有(yǒu)差别,大数据治理(lǐ)也包含元数据管理(lǐ)、数据质量管理(lǐ)、数据安全管理(lǐ)、数据标准管理(lǐ)、数据全生命周期管理(lǐ)等领域。但从本质上而言,由于大数据的4V特点,传统的数据治理(lǐ)模式和技术并不完全适配大数据治理(lǐ)。
首先,传统数据治理(lǐ)重点是建立数据标准,然后在数据的全生命周期过程中来执行数据标准,从而提升数据质量。而大数据治理(lǐ),数据来源多(duō)样化、数据结构多(duō)样化,数据传输存储形式的多(duō)样化……,这导致从一开始我们就很(hěn)难為(wèi)其定义数据标准。甚至有(yǒu)些数据都不知道他(tā)现在有(yǒu)什么价值,对于小(xiǎo)数据治理(lǐ)如果数据定义、数据价值说不清楚的话,是没有(yǒu)必要纳入数据治理(lǐ)范围的。但大数据治理(lǐ)就是在这大量的看起来没有(yǒu)关系的数据中找关系,没有(yǒu)价值的数据中挖掘价值,这就是大数据治理(lǐ)的魅力所在。
另外,传统的小(xiǎo)数据治理(lǐ)更多(duō)的是侧重于样本数据的治理(lǐ),数据库的模式是Schema on Write,即在数据治理(lǐ)之前要先定义好数据的Schema,包括了数据库的表、视图、存储过程、索引等,以及每个数据库条目对应的映射关系等,其采集、处理(lǐ)的过程是基于定义的Schema进行执行的。而大数据治理(lǐ)关注的全量数据,数据库模式是Schema on Read的模式,即在采集各类数据时不需要定义各种数据库对象,整个采集存储过程没有(yǒu)涉及到任何转置,原始数据没有(yǒu)因為(wèi)需要结构化或匹配差异系统而遭到破坏。
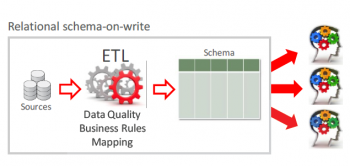
写时模型,作用(yòng)于数据源到数据汇聚存储之间,典型使用(yòng)就是传统数据库,数据在入库的时候需要预先设置schema。
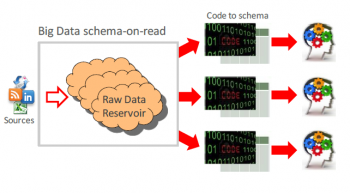
读时模型,作用(yòng)于数据汇聚存储到数据分(fēn)析之间,数据先存储,然后在需要分(fēn)析的时候再為(wèi)数据设置schema。
三、小(xiǎo)数据与大数据的區(qū)别
关于大数据与小(xiǎo)数据的區(qū)别网上有(yǒu)一段文(wén)字总结的非常精彩,这里分(fēn)享给大家:
第一:大数据重预测,小(xiǎo)数据重决定。大数据的分(fēn)析方式是自下而上的知识发现和预测过程,通过在一堆杂乱无章的数据中找到其背后的规律,所以大数据是从不确定性中找确定性。小(xiǎo)数据分(fēn)析通常会采用(yòng)统计學(xué)方法,分(fēn)析方式是自上而下。
第二:大数据重感知,小(xiǎo)数据重精准。大数据可(kě)以做整體(tǐ)上的感知,影响的范围更广,比如舆情监测、流感监测、网络营销、智慧城市等应用(yòng)。小(xiǎo)数据通常更关注数据的真实性和代表性,小(xiǎo)数据更聚焦。大数据往往包含了众多(duō)真假难辨的数据,而小(xiǎo)数据通常对于数据来源有(yǒu)严格的甄别,所以小(xiǎo)数据更精准。
第三:大数据重相关,小(xiǎo)数据重因果。大数据通常更注重是什么而不纠结于為(wèi)什么,通过相关性来给出问题的解决方案。小(xiǎo)数据是结果导向,更注重现象背后的内在机理(lǐ),更关注于為(wèi)什么。
第四:大数据重群體(tǐ),小(xiǎo)数据重个體(tǐ)。大数据的应用(yòng)通常更注重群體(tǐ)性行為(wèi)的分(fēn)析结果,比如网络消费的大数据分(fēn)析等,小(xiǎo)数据往往更注重于个體(tǐ)的行為(wèi)分(fēn)析结果,个性化是小(xiǎo)数据的重要特点。
数据表示的是过去,但表达的是未来。尽快大数据与小(xiǎo)数据从数据处理(lǐ)和应用(yòng)的角度有(yǒu)着很(hěn)大的區(qū)别,但是对于大数据和小(xiǎo)数据并不是“非黑即白”,而在我们的实际应用(yòng)过程中两者是相辅相成的。我们应用(yòng)数据不仅需要全量数据,也需要样本数据;不仅要了解相关性,更要明白因果关系;不仅要预见未来,更要量化自我。这就迫使我们从更广泛的角度理(lǐ)解小(xiǎo)数据,梳理(lǐ)小(xiǎo)数据与大数据的分(fēn)野,从而将相关思路投射、印证于小(xiǎo)数据,考察其核心特点和应用(yòng)特质。
四、小(xiǎo)数据治理(lǐ)靠“人工”
小(xiǎo)数据的治理(lǐ)十五字方针:理(lǐ)数据、建标准、接数据、抓运营、重实效。
理(lǐ)数据:小(xiǎo)数据治理(lǐ)追求的量化、精准,是以数据梳理(lǐ)為(wèi)切入点,摸清楚数据问题的“病因、病理(lǐ)”,然后“对症下药”。理(lǐ)数据通常采用(yòng)自上而下的方法,从数据问题结果出发,分(fēn)析数据问题发生的原因。通过数据梳理(lǐ)和溯源、识别关键数据资产,厘清数据资产分(fēn)布情况、数据质量情况、数据管理(lǐ)情况、数据量及存量、数据使用(yòng)情况等。
建标准:标准體(tǐ)系的建设是需要结合实际的业務(wù)应用(yòng)及管理(lǐ)需求,建立各专业数据定义和使用(yòng)的规范及标准,并逐步验证标准设计的合理(lǐ)性和可(kě)用(yòng)性。标准體(tǐ)系包含三个方面:一是制定数据标准,定义数据库表的Schema标准,数据分(fēn)类、数据编码的标准。二是制定数据管理(lǐ)标准,明确数据管理(lǐ)组织、明确数据管理(lǐ)权责,定义数据管理(lǐ)和使用(yòng)流程,制定数据管理(lǐ)制度和考核办法。三是制定数据交换标准,数据采集、存储、加工、使用(yòng)的技术标准、接口标准等。
接服務(wù):搭建数据治理(lǐ)平台,依据设计的数据标准和数据结构,结合当前应用(yòng)系统的使用(yòng)情况,选择合适的应用(yòng)系统,并配置相应的信息化基础设施资源,进行数据源的接入。依据已定义的数据标准、数据质量约束、数据接口规范执行,该过程中需要大量的人工干预以完成数据标准化、数据清洗、新(xīn)旧编码體(tǐ)系的映射等工作,形成一个标准化的数据环境。
抓运营:在数据的产生和使用(yòng)过程中,需要根据业務(wù)和管理(lǐ)的实际情况对数据标准、数据管理(lǐ)制度进行持续的迭代优化,确保数据标准化的落地,和在在長(cháng)期运行过程中的数据质量,防止数据质量的劣化。建體(tǐ)系容易、执行难,長(cháng)期有(yǒu)效的坚持运营才是数据治理(lǐ)成功之本。这个过程,也是培养数据治理(lǐ)人才、建设数据文(wén)化的过程。一旦数据治理(lǐ)形成一种文(wén)化,当人人都以数据说话、以数据思考、以数据决策的时候,就标志(zhì)着数据治理(lǐ)的成功,也标志(zhì)着以数据為(wèi)驱动的数字化时代来临。
重实效:根据不断变化的管理(lǐ)需求和应用(yòng)需求,适时的调整现有(yǒu)数据管理(lǐ)活动以及规划未来活动的框架,以适应不断变化的应用(yòng)需求。数据治理(lǐ)不是為(wèi)治理(lǐ)数据而治理(lǐ)数据,而是為(wèi)了更好的服務(wù)于业務(wù)和管理(lǐ)。数据治理(lǐ)要有(yǒu)一定的前瞻性,既要满足当前企业的业務(wù)和管理(lǐ)需求,也应满足企业未来的发展需求。
对于小(xiǎo)数据治理(lǐ)本质上是对利益相关者的沟通和协调,用(yòng)于确保管理(lǐ)和保护重要的关键数据。它涉及到个人,方法和创新(xīn)的简化协调,其顺序使其能(néng)够实现企业的数据价值。可(kě)见,小(xiǎo)数据的治理(lǐ)更多(duō)的是人的因素,所以我们说:小(xiǎo)数据治理(lǐ)靠“人工”。
五、大数据治理(lǐ)靠“智能(néng)”
大数据治理(lǐ)的六字方针:采、存、管、看、找、用(yòng)。
采。很(hěn)多(duō)数据价值的发现是来自对多(duō)源、异构数据的关联和对关联在一起的数据分(fēn)析。将多(duō)个不同的数据集融合在一起,可(kě)以使数据更丰富,使大数据分(fēn)析、预测更准确。然而,由于缺乏统一的数据标准设计,多(duō)源数据抽取和融合面临的困难是巨大的,人工智能(néng)技术的应用(yòng)就显得十分(fēn)重要。在数据实體(tǐ)识别方面,利用(yòng)自然语言处理(lǐ)和数据提取技术,从非结构化的文(wén)本中识别实體(tǐ)和实體(tǐ)之间的关联关系。例如:基于正则表达式的数据提取,将预先定义的正则表达式与文(wén)本匹配,把符合正则的数据定位出来。基于机器學(xué)习模型进行文(wén)本识别,预先将一部分(fēn)文(wén)本进行实體(tǐ)标注,产生一系列分(fēn)词,然后利用(yòng)这个模型对其他(tā)文(wén)档进行实體(tǐ)命名识别和标注。在这个过程中指代消解是自然语言处理(lǐ)中和实體(tǐ)识别关联的一个重要问题,比如:某医生,除了其姓名、职務(wù)、专业外,在文(wén)本中可(kě)能(néng)还会使用(yòng)某医生、某大夫、某专家等代称,如果文(wén)本中还涉及其他(tā)人物(wù),也用(yòng)了相关的代称,那么把这些代称应用(yòng)到正确的命名实體(tǐ)上就是指代消除。
存。与传统的小(xiǎo)数据治理(lǐ)不同,大数据环境下数据发展呈多(duō)样化,传统数据治理(lǐ)强调的建目标、建體(tǐ)系,似乎很(hěn)难适应大数据的多(duō)变。前文(wén)我们说过大数据的数据库模式是读时模式(Schema on Read),在数据采集、存储过程中并不关注数据的Schema (即数据结构),而是在数据分(fēn)析的时候再為(wèi)数据设置Schema,这就导致為(wèi)大数据建立统一的Schema标准是行不通的。在大数据治理(lǐ)过程中,强调的是数据的关联性,数据标准是被弱化的。
管。这部分(fēn)筆(bǐ)者认為(wèi)与传统的小(xiǎo)数据治理(lǐ)没有(yǒu)太大差别,核心是建立数据治理(lǐ)體(tǐ)系和長(cháng)效运行机制。
看。传统数据治理(lǐ)从理(lǐ)数据、建标准到接数据、抓运营的整个过程中,都是技术+管理(lǐ)共同推进的。也有(yǒu)人说,数据治理(lǐ)太过技术化,做完以后领导看不到效果。大数据治理(lǐ)是不仅让大数据能(néng)被管起来,还能(néng)被看到。在大数据治理(lǐ)项目建设过程中,利用(yòng)数据可(kě)视化技术,将底层的数据以可(kě)视化的方式展示出来,让用(yòng)户能(néng)够看到,在一定程度上也标志(zhì)着项目的成功。大数据治理(lǐ)中可(kě)视化应用(yòng)包括:数据资产地图、数据热度分(fēn)析、数据血缘分(fēn)析、数据质量问题分(fēn)析等。
找。在业務(wù)场景或业務(wù)环节中如果能(néng)够准确、高效的找到想要的数据?是大数据治理(lǐ)需要研究的一个课题。一般来说通过技术元数据查找相应的数据是比较容易实现的,但是数据治理(lǐ)目标是為(wèi)业務(wù)服務(wù)的,业務(wù)人员对技术元数据并不清楚、也不熟悉,如何让业務(wù)人员像用(yòng)搜索引擎一样能(néng)够找到自己想要的数据,这就需要建立业務(wù)元数据和技术元数据的匹配。而在大数据环境下,业務(wù)元数据和技术元数据的匹配关系显然不是通过“人工”的方式可(kě)以完成的,这就需要借助人工智能(néng)技术。在“找”数据的应用(yòng)中,知识图谱的应用(yòng)无疑是一种最佳解决方案。知识图谱通过从各种结构化数据、半结构化数据(形如HTML表格、文(wén)本文(wén)档中)抽取相关实體(tǐ)的属性-值对来丰富实體(tǐ)的描述,形成实體(tǐ)-属性-值,和实體(tǐ)-关系-实體(tǐ)的图谱描述,从而实现数据的快速定位和精准查询。
用(yòng)。大数据治理(lǐ)对大数据采、存、管、用(yòng)的规范化管理(lǐ),是要让数据不仅能(néng)够“管得住”、“找得到”,还要让数据能(néng)够“用(yòng)得好”。事实上,大数据的治理(lǐ)从来与大数据的应用(yòng)相伴相生的,离开应用(yòng)搞大数据治理(lǐ)是行不通。智能(néng)数据服務(wù)就是一个集治理(lǐ)与应用(yòng)為(wèi)一體(tǐ)的数据服務(wù)形式,通过数据服務(wù)的形式对外提供数据。也就是说,通过数据接口你就能(néng)够找到想要的数据,将数据接口嵌入到各个想要的业務(wù)系统中,遇到数据质量问题的时候也能(néng)直接定位到问题所在,而不再是等进入到数据治理(lǐ)系统里才能(néng)判定出血缘关系。
六、总结
在不久的将来,大数据、小(xiǎo)数据的界限或将被消除,取而代之的是“全域数据”。大数据、小(xiǎo)数据都是从技术层面对数据的描述或表达,而全域数据是从业務(wù)角度进行定义和描述。对于每个企业的全域数据覆盖范围是不一样的,全域数据涵盖了企业相关的内外部数据,与企业的业務(wù)和商(shāng)业性质息息相关。2019年“数据中台”的概念在全國(guó)范围内被推上了一个高潮,也有(yǒu)人将2019年称之為(wèi)数据中台的元年。所以,未来的数据治理(lǐ)会形成基于小(xiǎo)数据治理(lǐ)體(tǐ)系和大数据治理(lǐ)技术,在数据中台落地的数据治理(lǐ)新(xīn)模式。比如,未来智能(néng)交通领域,将有(yǒu)可(kě)能(néng)用(yòng)全量实时的数据,来感知城市每辆車(chē)所在的具體(tǐ)位置、每个红绿灯路口的車(chē)辆信息,并对这些情况进行全局调控,从而大幅提升城市交通运营效率。而实现这一目的,离不开对数据的挖掘和分(fēn)析,以及人工智能(néng)的深度學(xué)习。