
- 行业动态 >
- 资讯详情
人工智能(néng)在数据治理(lǐ)中的应用(yòng)
 2019/11/26
2019/11/26
 1964
文(wén)章来源:信息通信技术与政策 作者:李雨霏
1964
文(wén)章来源:信息通信技术与政策 作者:李雨霏



一、引言
伴随着大数据、云计算以及算法的发展,人工智能(néng)的浪潮从几年前一直延续至今,并且广泛应用(yòng)于多(duō)个行业和领域,成為(wèi)下一次科(kē)技革命的一个领军技术。同样,伴随着数据量与数据来源的猛增,数据治理(lǐ)也成為(wèi)了企业在充分(fēn)挖掘利用(yòng)数据价值过程中必不可(kě)少的环节,并逐渐发展為(wèi)企业的核心业務(wù)之一。
由于数据治理(lǐ)的输出是人工智能(néng)的输入,即经过数据治理(lǐ)后的大数据,因此数据治理(lǐ)与人工智能(néng)的发展存在相辅相成的关系。一方面,数据治理(lǐ)為(wèi)人工智能(néng)奠定基础。通过数据治理(lǐ),企业可(kě)以提升数据质量、增强数据合规性,从而為(wèi)人工智能(néng)的应用(yòng)提供高质量的合规数据。另一方面,人工智能(néng)对数据治理(lǐ)存在诸多(duō)优化作用(yòng)。通过人工智能(néng)技术,数据治理(lǐ)工作中的数据模型管理(lǐ)、元数据管理(lǐ)、主数据管理(lǐ)、数据质量管理(lǐ)、数据安全管理(lǐ)等方面智能(néng)化水平得到提升。
二、人工智能(néng)与数据治理(lǐ)的发展现状
(一)人工智能(néng)的发展现状
人工智能(néng)也称為(wèi)机器智能(néng),其概念最初是在20世纪50年代中期Dartmouth學(xué)会上提出,研究、开发用(yòng)于模拟、延伸和扩展人的智能(néng)的理(lǐ)论、方法、技术及应用(yòng)系统的一门新(xīn)的技术科(kē)學(xué)。在目前的學(xué)科(kē)體(tǐ)系下,人工智能(néng)属于计算机科(kē)學(xué)的一个分(fēn)支。人工智能(néng)的目的是通过了解智能(néng)的实质来提升机器的智能(néng)水平,并生产出一种新(xīn)的能(néng)以人类智能(néng)相似的方式做出反应的智能(néng)机器。人工智能(néng)的细分(fēn)领域很(hěn)多(duō),例如机器人、语言识别、图像识别、自然语言处理(lǐ)和专家系统等。
(1)在技术方面
以智能(néng)语音语义、计算机视觉等為(wèi)代表的技术不断取得突破,為(wèi)赋能(néng)各行业打下了坚实的基础。以智能(néng)语音语义為(wèi)例,语音识别应用(yòng)在纯净环境下表现趋近完美,机器翻译聚焦神经网络技术也实现了系统错误率60%的降低,在词嵌入及对话系统得到了長(cháng)足进步;以计算机视觉為(wèi)例,图像分(fēn)类已全面超越人类水平,在目标检测、语义分(fēn)割、目标跟踪等领域也实现了性能(néng)及精度的极大提升。
(2)在产业方面
近年来,以深度神经网络為(wèi)代表的人工智能(néng)技术及产业體(tǐ)系逐渐成型,正在深刻赋能(néng)各领域的应用(yòng)落地。如图1所示,人工智能(néng)产业技术體(tǐ)系以包含算法及软硬件实现的底层技术為(wèi)根基,以软件框架為(wèi)核心,通过基础应用(yòng)技术赋能(néng)上层应用(yòng)。
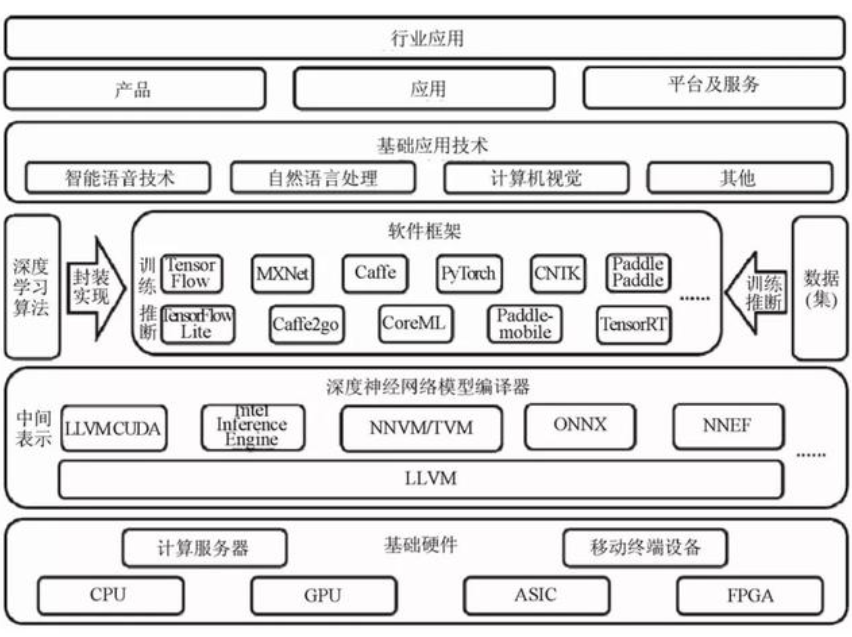
图1 人工智能(néng)产业體(tǐ)系架构图
(3)在应用(yòng)方面
随着人工智能(néng)在我國(guó)移动互联网、智能(néng)家居等领域的发展,我國(guó)人工智能(néng)的应用(yòng)持续高速成長(cháng)。由于人工智能(néng)包含的环节较多(duō),从基础技术层的数据平台、数据存储以及数据挖掘等,人工智能(néng)技术层的语音识别、自然语言处理(lǐ)、图像识别和生物(wù)识别等,到人工智能(néng)应用(yòng)层的工业4.0、无人驾驶汽車(chē)、智能(néng)家居、智能(néng)金融、智慧医疗、智能(néng)营销、智能(néng)教育以及智能(néng)农业等。随着人机交互水平的不断提升,智能(néng)音箱等新(xīn)型人机交互产品迅速发展;随着基础应用(yòng)的不断成熟,人工智能(néng)技术对如制造业、医疗、金融等垂直行业领域也在产生缓慢而深遠(yuǎn)的影响。
(二)数据治理(lǐ)的发展现状
随着大数据在各个行业领域应用(yòng)的不断深入,数据作為(wèi)基础性战略资源的地位日益凸显,数据标准化、数据确权、数据质量、数据安全、隐私保护、数据流通管控、数据共享开放等问题越来越受到國(guó)家、行业、企业各个层面的高度关注,这些内容都属于数据治理(lǐ)的范畴。因此,数据治理(lǐ)的概念就越来越多(duō)地受到关注,成為(wèi)目前大数据产业生态系统中的新(xīn)热点。
在20世纪80年代,随着数据随机存储和数据库技术的应用(yòng),产业界首次提出了数据管理(lǐ)的概念,这就是数据治理(lǐ)最早的起源。2009年,國(guó)际数据管理(lǐ)协会(DAMA)提出了DAMA数据管理(lǐ)理(lǐ)论框架模型,成為(wèi)目前行业最权威的数据管理(lǐ)理(lǐ)论模型。DAMA数据管理(lǐ)理(lǐ)论框架模型包括10个活动职能(néng),分(fēn)别是数据治理(lǐ)、数据架构管理(lǐ)、数据开发、数据操作管理(lǐ)、数据安全管理(lǐ)、参考数据和主数据管理(lǐ)、数据仓库和商(shāng)務(wù)智能(néng)管理(lǐ)、文(wén)档和内容管理(lǐ)、元数据管理(lǐ)和数据质量管理(lǐ)。
目前,企业数据治理(lǐ)已经形成了一套科(kē)學(xué)的管理(lǐ)范畴。从技术體(tǐ)系上来看,数据治理(lǐ)位于应用(yòng)和底层平台中间。数据治理(lǐ)包括两个重要方面:一是数据治理(lǐ)的核心活动职能(néng);二是确保这些活动职能(néng)落地实施的保障措施,包括组织架构、制度體(tǐ)系。数据治理(lǐ)在大数据应用(yòng)體(tǐ)系中,处于承上启下的重要地位。对上支持以价值挖掘為(wèi)导向的数据应用(yòng)开发,对下依托大数据平台实现数据全生命周期的管理(lǐ)。
2018年5月,银保监会印发《银行业金融机构数据治理(lǐ)指引的通知》,开启了行业数据治理(lǐ)的新(xīn)趋势,数据治理(lǐ)的概念从传统的数据企业走向能(néng)源、金融、工业、政務(wù)等多(duō)种行业。近年来,國(guó)内各行业大型企业纷纷发起企业内部数据治理(lǐ)项目,制定数据治理(lǐ)规范,成立专业的数据管理(lǐ)实體(tǐ)团队来开展企业数据治理(lǐ)工作。
三、数据治理(lǐ)為(wèi)人工智能(néng)奠定基础
大数据是不断采集、沉淀、分(fēn)类等的数据积累,而数据治理(lǐ)则為(wèi)大数据的呈现提供了更為(wèi)规范的模式。目前,大部分(fēn)人工智能(néng)的形式需要通过大量的数据运算实现,因此离不开大数据和数据治理(lǐ)的支持。人工智能(néng)需要依赖大数据平台和技术来帮助完成深度學(xué)习进化。
(1)数据治理(lǐ)為(wèi)人工智能(néng)优化数据质量
以深度學(xué)习為(wèi)代表的人工智能(néng)分(fēn)為(wèi)训练(Training)和推断(Inference)两个环节。深度學(xué)习训练算法的效果依赖于所输入的数据质量的优劣,如果输入的数据存在偏差,那么输出的算法也将产生偏差,这可(kě)能(néng)将直接导致所得结果的不可(kě)用(yòng)。数据治理(lǐ)在提升数据质量方面具有(yǒu)重要作用(yòng)。通过定义数据质量需求、定义数据质量测量指标、定义数据质量业務(wù)规则、制定数据质量改善方案、设计并实施数据质量管理(lǐ)工具、监控数据质量管理(lǐ)操作程序和绩效等数据质量管理(lǐ)环节,企业可(kě)以获得干净的、结构清晰的数据,為(wèi)深度學(xué)习等人工智能(néng)技术提供可(kě)信的数据输入。
(2)数据治理(lǐ)為(wèi)人工智能(néng)保障数据隐私
当前人工智能(néng)发展中面临的很(hěn)大制约就是数据权属和隐私保护问题。个人隐私数据之所以应该受到保护,就是因為(wèi)这些数据的滥用(yòng)有(yǒu)可(kě)能(néng)对个人造成巨大的财产甚至人身伤害。所谓隐私保护,其实就是对隐私数据的保护。最理(lǐ)想的情况是能(néng)够在产权层面确立相关个人作為(wèi)隐私数据的合法的唯一拥有(yǒu)者,或至少对隐私数据实际控制者的行為(wèi)严加管束,做到合法合规,这就离不开数据治理(lǐ)。数据治理(lǐ)工具从技术工具和保障措施等方面设计了保护隐私数据的诸多(duō)环节,可(kě)為(wèi)企业个人数据保护奠定基础,从而实现人工智能(néng)应用(yòng)的数据合规性。
四、人工智能(néng)在数据治理(lǐ)中的应用(yòng)
(一)数据模型管理(lǐ)
数据模型是数据治理(lǐ)的基础,一个完整的、可(kě)扩展的、稳定的数据模型可(kě)以清楚地表达企业内部各种业務(wù)主體(tǐ)之间的数据相关性,使不同部门的业務(wù)人员、应用(yòng)开发人员和系统管理(lǐ)人员获得关于企业业務(wù)数据的统一完整试图。数据模型包括概念模型、逻辑模型和物(wù)理(lǐ)模型。其中,概念模型一定程度上等同于传统数据库理(lǐ)论中所涉及的ER图(实體(tǐ)—联系图),反映了实體(tǐ)和实體(tǐ)之间的关系。
人工智能(néng)帮助实现概念模型与计算机模型的完美融合。ER图只能(néng)帮助我们理(lǐ)解客观世界的事物(wù),并非计算机可(kě)以实现的模型,因此在建立概念模型以后,还需将其转换為(wèi)计算机模型。知识图谱作為(wèi)人工智能(néng)的重要产物(wù)之一,是以图形(Graph)的方式展现实體(tǐ)、实體(tǐ)属性以及实體(tǐ)间的关系。目前,知识图谱普遍采用(yòng)了语义网络架构中RDF(Resource Deion Framework,资源模式框架)模型表示数据,其基本数据模型包括资源(Resource)、谓词(Predicate)和陈述(Statements)3个对象,用(yòng)于构建包含主體(tǐ)、属性和客體(tǐ)的知识图谱数据集。
(二)元数据管理(lǐ)
元数据是描述数据产品特征的任何信息,以及与企业认為(wèi)值得管理(lǐ)的其他(tā)数据产品的关系等。元数据也包含了许多(duō)主题领域,即业務(wù)分(fēn)析(如报表、用(yòng)户、绩效)、业務(wù)规则、数据整合(如数据源、数据转换规则)等。
(1)人工智能(néng)实现对非结构化数据的采集和关键信息的提取
在传统的元数据管理(lǐ)中,对于非结构化数据的元数据采集通常是通过创建非结构化数据的搜索索引的方式。语音识别、图像识别、文(wén)本分(fēn)析等技术帮助实现元数据的最初业務(wù)词库的构建,成為(wèi)提取各类有(yǒu)价值的非结构化元数据的资源池。
(2)人工智能(néng)帮助维护元数据
企业将元数据视為(wèi)数据的索引,因此元数据的质量至关重要。如果企业数据源存在不规则的数据并且这些不规则性可(kě)以利用(yòng)元数据體(tǐ)现,那么元数据可(kě)以辅助用(yòng)户理(lǐ)解这些复杂的数据。同时,在元数据的迁移和整合过程中,管理(lǐ)好元数据的质量也至关重要。人工智能(néng)在元数据质量维护的过程中不是一个“管理(lǐ)者”的角色,而是一个轻量又(yòu)关键的“技术者”的角色,它起到的作用(yòng)同在数据治理(lǐ)中提升数据质量的作用(yòng)类似,最终将消除在元数据存储或数据字典中重复、不一致的元数据,并通过元数据质量规则设定,提出可(kě)靠的质疑阈值。
(3)人工智能(néng)帮助实现元数据的整合
元数据的整合是在企业范围或在企业外部,采集相关的技术元数据和业務(wù)元数据,并将其存储进元数据存储库的过程。此过程在定义存储方式和跟踪机制的基础上,如果通过自动化实现将节约更多(duō)的人力成本,而人工智能(néng)在自动化中承担关键节点和优化节点的作用(yòng),解决诸如质量控制和语义筛选方面的问题。
(三)主数据管理(lǐ)
主数据指企业核心业務(wù)实體(tǐ)的数据,是在整个价值链上被重复、共享应用(yòng)于多(duō)个业務(wù)流程的、各个业務(wù)部门与各个系统之间共享的基础数据,是各业務(wù)应用(yòng)和各系统之间进行信息交互的基础。但是在主数据管理(lǐ)的过程中,企业可(kě)能(néng)面临如何在数量庞大的数据项中识别主数据、如何建立统一的主数据标准等问题。
(1)人工智能(néng)帮助企业识别主数据
确定主数据依赖于企业对于业務(wù)需求的理(lǐ)解和相应“黄金数据”的定义。通常来说,每个主数据主题域都有(yǒu)自己专用(yòng)的记录系统,并且分(fēn)散在各个业務(wù)系统中。人工智能(néng)相关技术可(kě)以帮助我们在所有(yǒu)数据中筛选出频繁出现或流动的数据,同时快速确定主数据的可(kě)靠与可(kě)信数据来源,构建完整的主数据试图。
(2)人工智能(néng)帮助定义和维护数据匹配规则
主数据管理(lǐ)面临的一个挑战是在多(duō)个系统中对于同一数据项进行匹配和合并,解决该挑战的一个方法是构建数据匹配规则,包括不同置信水平的匹配接受度。有(yǒu)些匹配需要极高的信任度,可(kě)以基于跨多(duō)个字段的准确数据匹配实现;有(yǒu)些匹配仅仅由于数据值的冲突,可(kě)以采用(yòng)较低的信任度。机器學(xué)习、自然语言处理(lǐ)可(kě)帮助建立重复识别匹配规则和匹配链接规则,在识别字段重复的主数据之后不进行自动合并,并确定与主数据相关的记录,建立交叉引用(yòng)关系。
数据质量是保证数据应用(yòng)的基础。衡量数据质量的指标體(tǐ)系包括完整性(数据是否缺失)、规范性(数据是否按照要求的规则存储)、一致性(数据的值是否存在信息含义上的冲突)、准确性(数据是否正确)、唯一性(数据是否是重复的)、时效性(数据是否及时反映客观事实)。对于任何一个企业而言,在实施数据质量提升方案之前,需要依据不同的业務(wù)规则和业務(wù)期望选择合适的数据质量指标體(tǐ)系,并进行数据的清洗。
人工智能(néng)定义转换规则,提取数据质量评估维度。数据质量改善最理(lǐ)想的模式是从数据源头剔除脏数据,但是这在现实中并不可(kě)行,其一是因為(wèi)数据源众多(duō)且难以控制数据源的数据质量,其二是直接从数据源头达标付出的成本过大。因此,根据业務(wù)期望,应针对性地提升各个业務(wù)線(xiàn)上数据流的数据质量。机器學(xué)习(如分(fēn)类學(xué)习、函数學(xué)习、回归)将通过提取有(yǒu)效的数据质量评估指标,最大化实现该指标下的数据质量的提升。
同时,监督學(xué)习、深度學(xué)习也将实现对数据清洗和数据质量的效果评估,进而改善转换规则和数据质量评估维度,并随着数据量和业務(wù)期望的逐渐变化,使数据质量提升方案动态更新(xīn)。
(五)数据安全
数据安全是指让信息或信息系统免受未经授权的访问、使用(yòng)、披露、破坏、修改、销毁的过程或状态。而数据安全治理(lǐ)不仅仅是安全工具或解决方案,而是基于战略、业務(wù)、应用(yòng)、安全和风险管理(lǐ)的有(yǒu)机整體(tǐ),从管理(lǐ)制度到工具支撑,从上层管理(lǐ)架构到下层技术实现,采取的一系列合适的措施。数据安全治理(lǐ)是人工智能(néng)在数据治理(lǐ)全过程中的重要应用(yòng)环节。
人工智能(néng)促进安全保障體(tǐ)系完善。依托人工智能(néng)引擎,通过对业務(wù)数据的获取、清洗、语义计算、数据挖掘、机器學(xué)习、知识图谱、认知计算等技术,将快速促进数据安全保障體(tǐ)系完善。
人工智能(néng)推进数据分(fēn)类分(fēn)级。应用(yòng)机器學(xué)习、自然语言处理(lǐ)和文(wén)本聚类分(fēn)类技术,能(néng)对数据进行基于内容的实时精准分(fēn)类分(fēn)级,而数据的分(fēn)类分(fēn)级是数据安全治理(lǐ)的核心环节。例如,利用(yòng)数据分(fēn)类引擎在邮件内容过滤、保密文(wén)件管理(lǐ)、情报分(fēn)析、反欺诈、数据防泄露等领域明显提升了安全性。
(六)其他(tā)方面
当前数据治理(lǐ)成熟度模型是定性模型,人工智能(néng)可(kě)以从两个方面实现对数据治理(lǐ)成熟度模型的改进,其一是结合企业自身的数据治理(lǐ)发展现状与数据治理(lǐ)理(lǐ)论框架,其二是通过自定义的多(duō)维度评估规则,实现成熟度模型的量化,在更细的颗粒度上提供切实可(kě)行的改进实施方案。
五、结束语
人工智能(néng)对于提升数据治理(lǐ)的智能(néng)化水平具有(yǒu)关键作用(yòng),因此也成為(wèi)数据治理(lǐ)发展的重要趋势。未来,通过人工智能(néng)技术降低数据治理(lǐ)的门槛将成為(wèi)数据治理(lǐ)发展的重要方向。人工智能(néng)与数据治理(lǐ)看起来是两项必须专业人士才可(kě)以操作的技术,但是如若将它们的使用(yòng)受限于懂技术的专家,缺少其他(tā)管理(lǐ)人员或业務(wù)人员的参与,将是一种对资源的浪费。因此,需要通过智能(néng)化嵌入手段不断提升数据治理(lǐ)工具的易用(yòng)性,使得数据治理(lǐ)的参与人员可(kě)以更為(wèi)便捷地使用(yòng)数据治理(lǐ)工具。自然语言问答(dá)、自然语言搜索、语音控制等人工智能(néng)技术的嵌入,将极大改善目前数据治理(lǐ)工作操作难的现状。
随着数据治理(lǐ)和人工智能(néng)两个领域的各自快速发展,未来二者的融合将会有(yǒu)更多(duō)场景和商(shāng)业模式。