
- 行业动态 >
- 资讯详情
浅谈数据质量管理(lǐ):為(wèi)了更清醒的数据
 2019/10/29
2019/10/29
 1814
文(wén)章来源:简书 原作者:idatadesign
1814
文(wén)章来源:简书 原作者:idatadesign



一、引言
战战兢兢地写下标题,得意下“清醒”这个词用(yòng)得真是独树一帜,跟外面那些妖艳贱货好不一样。我们常常说人要时刻保持清醒,这样才能(néng)不被假象所蒙蔽。那数据其实更需要这点,我们需要透过数据挖掘本质,如果数据是不具备完整人格的,缺失完整性、规范性、一致性等维度,那么我们看到的本质也是偏差的。开篇先鬼扯一下,详情请往下滑~
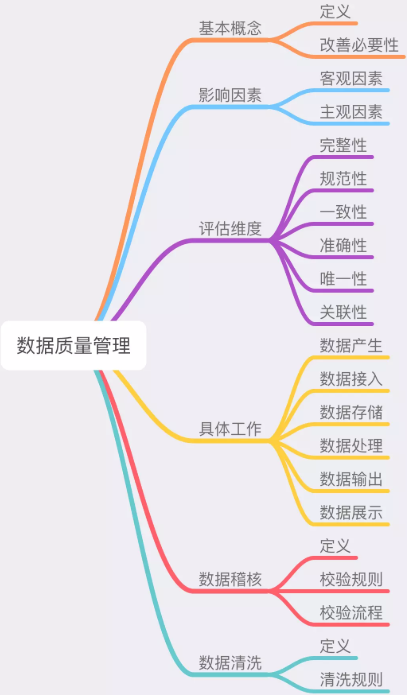
二、基本概念
数据质量管理(lǐ)是指為(wèi)了满足信息利用(yòng)的需要,对信息系统的各个信息采集点进行规范,包括建立模式化的操作规程、原始信息的校验、错误信息的反馈、矫正等一系列的过程。
数据质量管理(lǐ)不是一时的数据治理(lǐ)手段,而是循环的管理(lǐ)过程。
数据质量管理(lǐ)不仅包含了对数据质量的改善,同时还包含了对组织的改善。
為(wèi)什么有(yǒu)这么多(duō)人强调改善数据质量管理(lǐ)的重要性,用(yòng)一种很(hěn)抽象的比喻描述,如果把整个数据应用(yòng)比作人體(tǐ)的话,那好的数据就相当于新(xīn)鲜和沸腾的血液,能(néng)让我们的身體(tǐ)充满活力,高效地工作思考。而质量差的血液携带废物(wù)和毒素,随着毒素越积越多(duō),血液以及血管就会发生病变,血液流经的全身各处器官也会大受影响。如果非要要具體(tǐ)的数据证明,我摘取了一些专家的统计:
据专家估计,由于用(yòng)户拒绝不可(kě)靠的数据,导致多(duō)达70%的数据仓库项目遭到失败。
据专家估计,糟糕的数据通过使收入受损而会耗费商(shāng)业机构多(duō)达10%~20%的操作总预算。而且,IT部门预算的40%50%之多(duō)可(kě)能(néng)都花(huā)在了纠正由糟糕的数据所引起的错误上(English,1999)。
专家认為(wèi),由于客户的死亡、离婚、结婚或调离,客户文(wén)件中的记录在一个月之内会有(yǒu)2%变得过时(Betts,2002)。
三、影响因素
那什么会影响数据质量呢(ne)?其实简单就分(fēn)為(wèi)2个因素。
客观因素:在数据各环节流转中,由于系统异常和流程设置不当等因素,从而引起的数据质量问题。
主观因素:在数据各环节处理(lǐ)中,由于人员素质低和管理(lǐ)缺陷等因素,从而操作不当而引起的数据质量问题。
在此附上数据的生命周期图,包括各环节的数据流转和数据处理(lǐ)。

四、评估维度
那怎么样才算质量好的数据呢(ne)?借用(yòng)数据质量评估六要素,顺便附上自己的一些解析:
完整性 Completeness
数据是完整不缺失的。例如人员信息完整涵盖性别、年龄等。
规范性 Conformity
数据是规范统一的。例如时间信息都以yyyy-mm-dd格式存储。
一致性 Consistency
同源或跨源的数据是一致不冲突的。例如同一个人在不同源取过来的性别都是一致的。
准确性 Accuracy
数据是准确合理(lǐ)的。例如年龄在合理(lǐ)范围内。
唯一性 Uniqueness
数据是唯一不重复的。例如同一个ID没有(yǒu)重复记录。
关联性 Integration
数据的关联是不缺失的。例如两张表建立的关联关系存在,不丢失数据。
五、具體(tǐ)工作
如何通过具體(tǐ)工作来贯彻落实数据质量管理(lǐ)呢(ne)?由于数据质量管理(lǐ)是贯穿数据整个生命周期的,所以根据数据的各环节进行分(fēn)点描述:
数据产生---控制外部数据源
(1)非开放式输入,避免用(yòng)户自己输入,尽量提供用(yòng)户选择项。设定字典表,例如性别不允许输入(男、女、未知)以外的内容
(2)开放式输入,增加提示或者校验。例如设定临界值,例如年龄填了-1或者200,不允许输入。
数据接入---保持多(duō)点录入一致
建立统一的数据體(tǐ)系,例如指标(度量)、口径(维度)。
数据存储---保持数据结构统一
建立标准的数据结构,例如字段格式,系统提前定义好一种时间默认格式為(wèi)yyyy-mm-dd。
数据处理(lǐ)---保持处理(lǐ)流程一致,该点包括数据稽核和数据清洗
按照标准的处理(lǐ)流程,例如统一的清洗规则等。
数据输出---保持数据结构统一
对数据处理(lǐ)后的结果进行保存时,按照数据存储的要求,进行标准化的统一管理(lǐ)。
数据展示---持续监测分(fēn)析数据
设立监测规则不断发现问题,通过解决问题不断改进规则。
六、数据稽核
(1)定义
数据稽核是指实现数据的完整性和一致性检查,提升数据质量,数据稽核是一个从数据采集,预处理(lǐ),比对,分(fēn)析,预警,通知,问题修复的完整数据质量管控链条。
(2)校验规则
关联性检查:两个数据表的key值关联是否存在。
行级别:两个数据表的数据量是否一致。
列级别:两个数据表的表结构是否一致,如字段数量、字段类型和宽度等是否一致。
内容级别:两个数据表的内容是否一致。其一数据表的内容是否缺失。
(3)校验流程
1、配置校验规则,例如字段映射等。
2、配置调度规则,例如调度频率等。
3、配置报表模板,例如稽核结果等。

七、数据清洗
(1)定义
数据清洗是指发现并纠正数据文(wén)件中可(kě)识别的错误的最后一道程序,包括检查数据一致性,处理(lǐ)无效值和缺失值等。与问卷审核不同,录入后的数据清理(lǐ)一般是由计算机而不是人工完成。
(2)清洗规则
1)缺失值处理(lǐ)
根据同一字段的数据填充,例如均值、中位数、众数等。
根据其他(tā)字段的数据填充,例如通过身份证件号码取出生日期等。
设定一个全局变量,例如缺失值用(yòng)“unknown ”等填充。
直接剔除,避免缺失值过多(duō)影响结果。
建模法,可(kě)以用(yòng)回归、使用(yòng)贝叶斯形式化方法的基于推理(lǐ)的工具或决策树归纳确定。
2)重复值处理(lǐ)
根据主键去重,利用(yòng)工具去除重复记录。
根据组合去重,编写一系列的规则,对重复情况复杂的数据进行去重。例如不同渠道来的客户数据,可(kě)以通过相同的关键信息进行匹配,合并去重。
3)异常值处理(lǐ)
根据同一字段的数据填充,例如均值、中位数、众数等。
直接剔除,避免异常值过多(duō)影响结果。
设為(wèi)缺失值,可(kě)以按照处理(lǐ)缺失值的方法来处理(lǐ)。
4)不一致值处理(lǐ)
从根源入手,建立统一的数据體(tǐ)系,例如指标(度量)、口径(维度)。
从结果入手,设立中心标准,对不同来源数据进行值域对照。
5)丢失关联值处理(lǐ)
重新(xīn)建立关联。