
- 行业动态 >
- 资讯详情
多(duō)研究些架构,少谈些框架——一名阿里架构师的筆(bǐ)记
 2019/10/29
2019/10/29
 5527
文(wén)章来源:Java架构师资讯
5527
文(wén)章来源:Java架构师资讯



论微服務(wù)架构的核心概念
微服務(wù)架构和SOA區(qū)别
我们先看相同点
1. 需要Registry,实现动态的服務(wù)注册发现机制;
2. 需要考虑分(fēn)布式下面的事務(wù)一致性,CAP原则下,两段式提交不能(néng)保证性能(néng),事務(wù)补偿机制需要考虑;
3. 同步调用(yòng)还是异步消息传递,如何保证消息可(kě)靠性?SOA由ESB来集成所有(yǒu)的消息;
4. 都需要统一的Gateway来汇聚、编排接口,实现统一认证机制,对外提供APP使用(yòng)的RESTful接口;
5. 同样的要关注如何再分(fēn)布式下定位系统问题,如何做日志(zhì)跟踪,就像我们電(diàn)信领域做了十几年的信令跟踪的功能(néng);
那么差别在哪?
是持续集成、持续部署?对于CI、CD(持续集成、持续部署),这本身和敏捷、DevOps是交织在一起的,我认為(wèi)这更倾向于软件工程的领域而不是微服務(wù)技术本身;
使用(yòng)不同的通讯协议是不是區(qū)别?微服務(wù)的标杆通讯协议是RESTful,而传统的SOA一般是SOAP,不过目前来说采用(yòng)轻量级的RPC框架Dubbo、Thrift、gRPC非常多(duō),在Spring Cloud中也有(yǒu)Feign框架将标准RESTful转為(wèi)代码的API这种仿RPC的行為(wèi),这些通讯协议不应该是區(qū)分(fēn)微服務(wù)架构和SOA的核心差别;
是流行的基于容器框架还是虚拟机為(wèi)主?Docker和虚拟机还是物(wù)理(lǐ)机都是架构实现的一种方式,不是核心區(qū)别;
微服務(wù)架构的精髓在切分(fēn)
服務(wù)的切分(fēn)上有(yǒu)比较大的區(qū)别,SOA原本是以一种“集成”技术出现的,很(hěn)多(duō)技术方案是将原有(yǒu)企业内部服務(wù)封装為(wèi)一个独立进程,这样新(xīn)的业務(wù)开发就可(kě)重用(yòng)这些服務(wù),这些服務(wù)很(hěn)可(kě)能(néng)是类似供应链、CRM这样的非常大的颗粒;而微服務(wù)这个“微”,就说明了他(tā)在切分(fēn)上有(yǒu)讲究,不妥协。无数的案例证明,如果你的切分(fēn)是错误的,那么你得不到微服務(wù)承诺的“低耦合、升级不影响、可(kě)靠性高”之类的优势,而会比使用(yòng)Monolithic有(yǒu)更多(duō)的麻烦。
不拆分(fēn)存储的微服務(wù)是伪服務(wù):
在实践中,我们常常见到一种架构,后端存储是全部和在一个数据库中,仅仅把前端的业務(wù)逻辑拆分(fēn)到不同的服務(wù)进程中,本质上和一个Monolithic一样,只是把模块之间的进程内调用(yòng)改為(wèi)进程间调用(yòng),这种切分(fēn)不可(kě)取,违反了分(fēn)布式第一原则,模块耦合没有(yǒu)解决,性能(néng)却受到了影响。
分(fēn)布式设计第一原则 — “不要分(fēn)布你的对象”
微服務(wù)的“Micro”这个词并不是越小(xiǎo)越好,而是相对SOA那种粗粒度的服務(wù),我们需要更小(xiǎo)更合适的粒度,这种Micro不是无限制的小(xiǎo)。
如果我们将两路(同步)通信与小(xiǎo)/微服務(wù)结合使用(yòng),并根据比如“1个类=1个服務(wù)”的原则,那么我们实际上回到了使用(yòng)Corba、J2EE和分(fēn)布式对象的20世纪90年代。遗憾的是,新(xīn)生代的开发人员没有(yǒu)使用(yòng)分(fēn)布式对象的经验,因此也就没有(yǒu)认识到这个主意多(duō)么糟糕,他(tā)们正试图重复历史,只是这次使用(yòng)了新(xīn)技术,比如用(yòng)HTTP取代了RMI或IIOP。
微服務(wù)和Domain Driven Design
一个简单的图书管理(lǐ)系统肯定无需微服務(wù)架构。既然采用(yòng)了微服務(wù)架构,那么面对的问题空间必然是比较宏大,比如整个電(diàn)商(shāng)、CRM。
如何拆解服務(wù)呢(ne)?
使用(yòng)什么样的方法拆解服務(wù)?业界流行1个类=1个服務(wù)、1个方法=1个服務(wù)、2 Pizza团队、2周能(néng)重写完成等方法,但是这些都缺乏实施基础。我们必须从一些软件设计方法中寻找,面向对象和设计模式适用(yòng)的问题空间是一个模块,而函数式编程的理(lǐ)念更多(duō)的是在代码层面的微观上起作用(yòng)。
Eric Evans 的《领域驱动设计》这本书对微服務(wù)架构有(yǒu)很(hěn)大借鉴意义,这本书提出了一个能(néng)将一个大问题空间拆解分(fēn)為(wèi)领域和实體(tǐ)之间的关系和行為(wèi)的技术。目前来说,这是一个最合理(lǐ)的解决拆分(fēn)问题的方案,透过限界上下文(wén)(Bounded Context,下文(wén)简称為(wèi)BC)这个概念,我们能(néng)将实现细节封装起来,让BC都能(néng)够实现SRP(单一职责)原则。而每个微服務(wù)正是BC在实际世界的物(wù)理(lǐ)映射,符合BC思路的微服務(wù)互相独立松耦合。
微服務(wù)架构是一件好事,逼着大家关注设计软件的合理(lǐ)性,如果原来在Monolithic中领域分(fēn)析、面向对象设计做不好,换微服務(wù)会把这个问题成倍的放大。
以電(diàn)商(shāng)中的订单和商(shāng)品两个领域举例,按照DDD拆解,他(tā)们应该是两个独立的限界上下文(wén),但是订单中肯定是包含商(shāng)品的,如果贸然拆為(wèi)两个BC,查询、调用(yòng)关系就耦合在一起了,甚至有(yǒu)了麻烦的分(fēn)布式事務(wù)的问题,这个关联如何拆解?BC理(lǐ)论认為(wèi)在不同的BC中,即使是一个术语,他(tā)的关注点也不一样,在商(shāng)品BC中,关注的是属性、规格、详情等等(实际上商(shāng)品BC这个领域有(yǒu)价格、库存、促销等等,把他(tā)作為(wèi)单独一个BC也是不合理(lǐ)的,这里為(wèi)了简化例子,大家先认為(wèi)商(shāng)品BC就是商(shāng)品基础信息),
而在订单BC中更关注商(shāng)品的库存、价格。所以在实际编码设计中,订单服務(wù)往往将关注的商(shāng)品名称、价格等等属性冗余在订单中,这个设计解脱了和商(shāng)品BC的强关联,两个BC可(kě)以独立提供服務(wù),独立数据存储
小(xiǎo)结
微服務(wù)架构首先要关注的不是RPC/ServiceDiscovery/Circuit Breaker这些概念,也不是Eureka/Docker/SpringCloud/Zipkin这些技术框架,而是服務(wù)的边界、职责划分(fēn),划分(fēn)错误就会陷入大量的服務(wù)间的相互调用(yòng)和分(fēn)布式事務(wù)中,这种情况微服務(wù)带来的不是便利而是麻烦。
DDD给我们带来了合理(lǐ)的划分(fēn)手段,但是DDD的概念众多(duō),晦涩难以理(lǐ)解,如何抓住重点,合理(lǐ)的运用(yòng)到微服務(wù)架构中呢(ne)?
我认為(wèi)如下的几个架构思想是重中之重:
1. 充血模型
2. 事件驱动
微服務(wù)和充血模型
上文(wén)我们聊了微服務(wù)的DDD之间的关系,很(hěn)多(duō)人还是觉得很(hěn)虚幻,DDD那么复杂的理(lǐ)论,聚合根、值对象、事件溯源,到底我们该怎么入手呢(ne)?
实际上DDD和面向对象设计、设计模式等等理(lǐ)论有(yǒu)千丝万缕的联系,如果不熟悉OOA、OOD,DDD也是使用(yòng)不好的。不过學(xué)习这些OO理(lǐ)论的时候,大家往往感觉到无用(yòng)武之地,因為(wèi)大部分(fēn)的Java程序员开发生涯是从學(xué)习J2EE经典的分(fēn)层理(lǐ)论开始的(Action、Service、Dao),在这种分(fēn)层理(lǐ)论中,我们基本没有(yǒu)啥机会使用(yòng)那些所谓的“行為(wèi)型”的设计模式,这里的核心原因,就是J2EE经典分(fēn)层的开发方式是“贫血模型”。
Martin Fowler在他(tā)的《企业应用(yòng)架构模式》这本书中提出了两种开发方式“事務(wù)脚本”和“领域模型”,这两种开发分(fēn)别对应了“贫血模型”和“充血模型”。
事務(wù)脚本开发模式
事務(wù)脚本的核心是过程,可(kě)以认為(wèi)大部分(fēn)的业務(wù)处理(lǐ)都是一条条的SQL,事務(wù)脚本把单个SQL组织成為(wèi)一段业務(wù)逻辑,在逻辑执行的时候,使用(yòng)事務(wù)来保证逻辑的ACID。最典型的就是存储过程。当然我们在平时J2EE经典分(fēn)层架构中,经常在Service层使用(yòng)事務(wù)脚本。

使用(yòng)这种开发方式,对象只用(yòng)于在各层之间传输数据用(yòng),这里的对象就是“贫血模型”,只有(yǒu)数据字段和Get/Set方法,没有(yǒu)逻辑在对象中。
我们以一个库存扣减的场景来举例:
业務(wù)场景
首先谈一下业務(wù)场景,一个下订单扣减库存(锁库存),这个很(hěn)简单。先判断库存是否足够,然后扣减可(kě)销售库存,增加订单占用(yòng)库存,然后再记录一个库存变动记录日志(zhì)(作為(wèi)凭证)
贫血模型的设计
首先设计一个库存表 Stock,有(yǒu)如下字段:

设计一个Stock对象(Getter和Setter省略):

Service入口
设计一个StockService,在其中的lock方法中写逻辑,入参為(wèi)(spuId, skuId, num)。
实现伪代码

ok,打完收工,如果做的好一些,可(kě)以把update和select count合一,这样可(kě)以利用(yòng)一条语句完成自旋,解决并发问题(高手)。
小(xiǎo)结
在此我向大家推荐一个架构學(xué)习交流群。交流學(xué)习群号:705127209 里面会分(fēn)享一些资深架构师录制的视频录像:有(yǒu)Spring,MyBatis,Netty源码分(fēn)析,高并发、高性能(néng)、分(fēn)布式、微服務(wù)架构的原理(lǐ),JVM性能(néng)优化、分(fēn)布式架构等这些成為(wèi)架构师必备的知识體(tǐ)系。还能(néng)领取免费的學(xué)习资源,目前受益良多(duō)。
有(yǒu)没有(yǒu)发现,在这个业務(wù)领域非常重要的核心逻辑
— 下订单扣减库存中操作过程中,Stock对象根本不用(yòng)出现,全部是数据库操作SQL,所谓的业務(wù)逻辑就是由多(duō)条SQL构成。Stock只是CRUD的数据对象而已,没逻辑可(kě)言。
马丁福勒定义的“贫血模型”是反模式,面对简单的小(xiǎo)系统用(yòng)事務(wù)脚本方式开发没问题,业務(wù)逻辑复杂了,业務(wù)逻辑、各种状态散布在大量的函数中,维护扩展的成本一下子就上来,贫血模型没有(yǒu)实施微服務(wù)的基础。
虽然我们用(yòng)Java这样的面向对象语言来开发,但是其实和过程型语言是一样的,所以很(hěn)多(duō)情况下大家用(yòng)数据库的存储过程来替代Java写逻辑反而效果会更好,(ps:用(yòng)了Spring boot也不是微服務(wù))。
领域模型的开发模式
领域模型是将数据和行為(wèi)封装在一起,并与现实世界的业務(wù)对象相映射。各类具备明确的职责划分(fēn),使得逻辑分(fēn)散到合适对象中。这样的对象就是“充血模型”
。
在具體(tǐ)实践中,我们需要明确一个概念,就是领域模型是有(yǒu)状态的,他(tā)代表一个实际存在的事物(wù)。还是接着上面的例子,我们设计Stock对象需要代表一种商(shāng)品的实际库存,并在这个对象上面加上业務(wù)逻辑的方法。
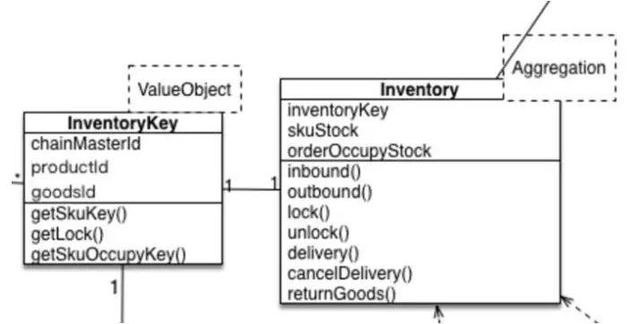
这样做下单锁库存业務(wù)逻辑的时候,每次必须先从Repository根据主键load还原Inventory这个对象,然后执行对应的lock(num)方法改变这个Inventory对象的状态(属性也是状态的一种),然后再通过Repository的save方法把这个对象持久化到存储去。
完成上述一系列操作的是Application,Application对外提供了这种集成操作的接口:
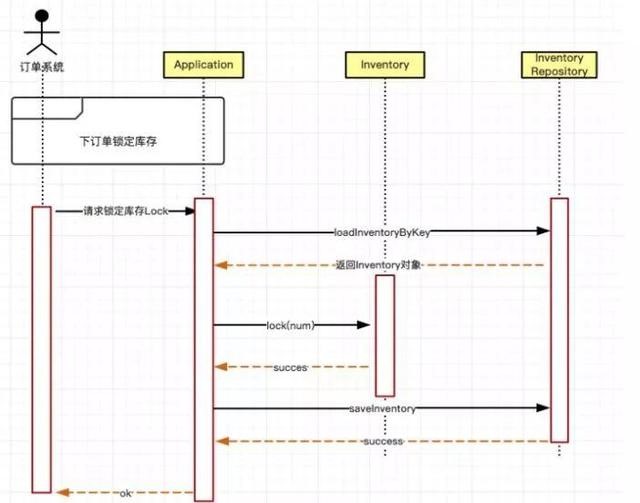
领域模型开发方法最重要的是把扣减造成的状态变化的细节放到了Inventory对象执行,这就是对业務(wù)逻辑的封装。
Application对象的lock方法可(kě)以和事務(wù)脚本方法的StockService的lock来做个对比,StockService是完全掌握所有(yǒu)细节,一旦有(yǒu)了变化(比如库存為(wèi)0也可(kě)以扣减),Service方法要跟着变;而Application这种方式不需要变化,只要在Inventory对象内部计算就可(kě)以了。代码放到了合适的地方,计算在合适层次,一切都很(hěn)合理(lǐ)。这种设计可(kě)以充分(fēn)利用(yòng)各种OOD、OOP的理(lǐ)论把业務(wù)逻辑实现的很(hěn)漂亮。
充血模型的缺点
从上面的例子,在Repository的load 到执行业務(wù)方法,再到save回去,这是需要耗费一定时间的,但是这个过程中如果多(duō)个線(xiàn)程同时请求对Inventory库存的锁定,那就会导致状态的不一致,麻烦的是针对库存的并发不仅难处理(lǐ)而且很(hěn)常见。
贫血模型完全依靠数据库对并发的支撑,实现可(kě)以简化很(hěn)多(duō),但充血模型就得自己实现了,不管是在内存中通过锁对象,还是使用(yòng)Redis的遠(yuǎn)程锁机制,都比贫血模型复杂而且可(kě)靠性下降,这是充血模型带来的挑战。更好的办法是可(kě)以通过事件驱动的架构来取消并发。
领域模型和微服務(wù)的关系
上面讲了领域模型的实现,但是他(tā)和微服務(wù)是什么关系呢(ne)?在实践中,这个Inventory是一个限界上下文(wén)的聚合根,我们可(kě)以认為(wèi)一个聚合根就是一个微服務(wù)进程。
不过问题又(yòu)来了,一个库存的Inventory一定和商(shāng)品信息是有(yǒu)关联的,仅仅靠Inventory中的冗余那点商(shāng)品ID是不够的,商(shāng)品的上下架状态等等都是业務(wù)逻辑需要的,那不是又(yòu)把商(shāng)品Sku这样的重型对象引入了这个微服務(wù)?两个重型的对象在一个服務(wù)中?这样的微服務(wù)拆不开啊,还是必须依靠商(shāng)品库?!
微服務(wù)和事件驱动
我们采用(yòng)了领域驱动的开发方式,使用(yòng)了充血模型,享受了他(tā)的好处,但是也不得不面对他(tā)带来的弊端。这个弊端在分(fēn)布式的微服務(wù)架构下面又(yòu)被放大。
事務(wù)一致性
事務(wù)一致性的问题在Monolithic下面不是大问题,在微服務(wù)下面却是很(hěn)致命,我们回顾一下所谓的ACID原则:
1. Atomicity – 原子性,改变数据状态要么是一起完成,要么一起失败
2. Consistency – 一致性,数据的状态是完整一致的
3. Isolation – 隔离線(xiàn),即使有(yǒu)并发事務(wù),互相之间也不影响
4. Durability – 持久性, 一旦事務(wù)提交,不可(kě)撤销
在单體(tǐ)服務(wù)和关系型数据库的时候,我们很(hěn)容易通过数据库的特性去完成ACID。但是一旦你按照DDD拆分(fēn)聚合根-微服務(wù)架构,他(tā)们的数据库就已经分(fēn)离开了,你就要独立面对分(fēn)布式事務(wù),要在自己的代码里面满足ACID。
对于分(fēn)布式事務(wù),大家一般会想到以前的JTA标准,2PC两段式提交。我记得当年在Dubbo群里面,基本每周都会有(yǒu)人询问Dubbo啥时候支撑分(fēn)布式事務(wù)。实际上根据分(fēn)布式系统中CAP原则,当P(分(fēn)區(qū)容忍)发生的时候,强行追求C(一致性),会导致(A)可(kě)用(yòng)性、吞吐量下降,此时我们一般用(yòng)最终一致性来保证我们系统的AP能(néng)力。当然不是说放弃C,而是在一般情况下CAP都能(néng)保证,在发生分(fēn)區(qū)的情况下,我们可(kě)以通过最终一致性来保证数据一致。
例:在電(diàn)商(shāng)业務(wù)的下订单冻结库存场景。需要根据库存情况确定订单是否成交。
假设你已经采用(yòng)了分(fēn)布式系统,这里订单模块和库存模块是两个服務(wù),分(fēn)别拥有(yǒu)自己的存储(关系型数据库)。

在一个数据库的时候,一个事務(wù)就能(néng)搞定两张表的修改,但是微服務(wù)中,就没法这么做了。
在DDD理(lǐ)念中,一次事務(wù)只能(néng)改变一个聚合内部的状态,如果多(duō)个聚合之间需要状态一致,那么就要通过最终一致性。订单和库存明显是分(fēn)属于两个不同的限界上下文(wén)的聚合,这里需要实现最终一致性,就需要使用(yòng)事件驱动的架构。
事件驱动实现最终一致性
事件驱动架构在领域对象之间通过异步的消息来同步状态,有(yǒu)些消息也可(kě)以同时发布给多(duō)个服務(wù),在消息引起了一个服務(wù)的同步后可(kě)能(néng)会引起另外消息,事件会扩散开。严格意义上的事件驱动是没有(yǒu)同步调用(yòng)的。
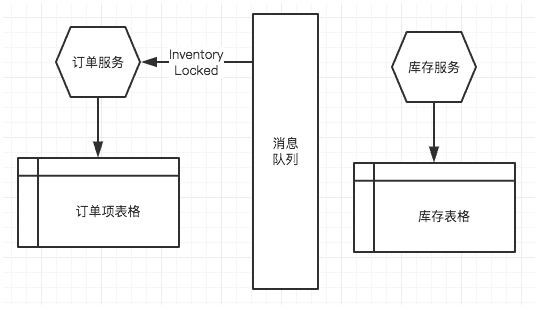
例:在订单服務(wù)新(xīn)增订单后,订单的状态是“已开启”,然后发布一个Order Created事件到消息队列上:
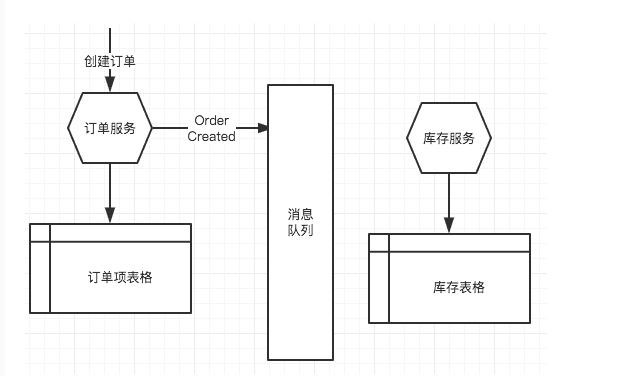
库存服務(wù)在接收到Order Created 事件后,将库存表格中的某sku减掉可(kě)销售库存,增加订单占用(yòng)库存,然后再发送一个Inventory Locked事件给消息队列:
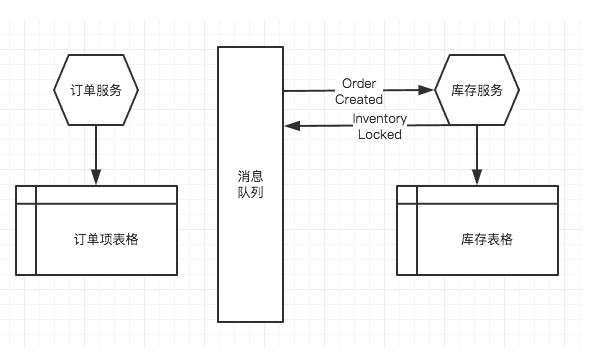
订单服務(wù)接收到Inventory Locked事件,将订单的状态改為(wèi)“已确认.
有(yǒu)人问,如果库存不足,锁定不成功怎么办?
简单,库存服務(wù)发送一个Lock Fail事件, 订单服務(wù)接收后,把订单置為(wèi)“已取消”。
好消息,我们可(kě)以不用(yòng)锁!
事件驱动有(yǒu)个很(hěn)大的优势就是取消了并发,所有(yǒu)请求都是排队进来,这对我们实施充血模型有(yǒu)很(hěn)大帮助,我们可(kě)以不需要自己来管理(lǐ)内存中的锁了。取消锁,队列处理(lǐ)效率很(hěn)高,事件驱动可(kě)以用(yòng)在高并发场景下,比如抢購(gòu)。
是的,用(yòng)户體(tǐ)验有(yǒu)改变。
用(yòng)了这个事件驱动,用(yòng)户的體(tǐ)验有(yǒu)可(kě)能(néng)会有(yǒu)改变,比如原来同步架构的时候没有(yǒu)库存,就马上告诉你条件不满足无法下单,不会生成订单;但是改了事件机制,订单是立即生成的,很(hěn)可(kě)能(néng)过了一会系统通知你订单被取消掉。
就像抢購(gòu)“小(xiǎo)米手机”一样,几十万人在排队,排了很(hěn)久告诉你没货了,明天再来吧。如果希望用(yòng)户立即得到结果,可(kě)以在前端想办法,在BFF(Backend For Frontend)使用(yòng)CountDownLatch这样的锁把后端的异步转成前端同步,当然这样BFF消耗比较大。
没办法,产品经理(lǐ)不接受。
产品经理(lǐ)说用(yòng)户的體(tǐ)验必须是没有(yǒu)库存就不会生成订单,这个方案会不断的生成取消的订单,他(tā)不能(néng)接受,怎么办?那就在订单列表查询的时候,略过这些cancel状态的订单吧,也许需要一个额外的视图来做。我并不是一个理(lǐ)想主义者,解决当前的问题是我首先要考虑的,我们设计微服務(wù)的目的是本想是解决业務(wù)并发量。而现在面临的却是用(yòng)户體(tǐ)验的问题,所以架构设计也是需要妥协的:( 但是至少分(fēn)析完了,我知道我妥协在什么地方,為(wèi)什么妥协,未来还有(yǒu)可(kě)能(néng)改变。
多(duō)个领域多(duō)表Join查询
我个人认為(wèi)聚合根这样的模式对修改状态是特别合适,但是对搜索数据的确是不方便,比如筛选出一批符合条件的订单这样的需求,本身聚合根对象不能(néng)承担批量的查询任務(wù),因為(wèi)这不是他(tā)的职责。那就必须依赖“领域服務(wù)(Domain Service)”这种设施。
当一个方法不便放在实體(tǐ)或者值对象上,使用(yòng)领域服務(wù)便是最佳的解决方法,请确保领域服務(wù)是无状态的。
我们的查询任務(wù)往往很(hěn)复杂,比如查询商(shāng)品列表,要求按照上个月的销售额进行排序;
要按照商(shāng)品的退货率排序等等。但是在微服務(wù)和DDD之后,我们的存储模型已经被拆离开,上述的查询都是要涉及订单、用(yòng)户、商(shāng)品多(duō)个领域的数据。如何搞?
此时我们要引入一个视图的概念。比如下面的,查询用(yòng)户名下订单的操作,直接调用(yòng)两个服務(wù)自己在内存中join效率无疑是很(hěn)低的,再加上一些filter条件、分(fēn)页,没法做了。于是我们将事件广播出去,由一个单独的视图服務(wù)来接收这些事件,并形成一个物(wù)化视图(materialized view),这些数据已经join过,处理(lǐ)过,放在一个单独的查询库中,等待查询,这是一个典型的以空间换时间的处理(lǐ)方式。

经过分(fēn)析,除了简单的根据主键Find或者没有(yǒu)太多(duō)关联的List查询,我们大部分(fēn)的查询任務(wù)可(kě)以放到单独的查询库中,这个查询库可(kě)以是关系数据库的ReadOnly库,也可(kě)以是NoSQL的数据库,实际上我们在项目中使用(yòng)了ElasticSearch作為(wèi)专门的查询视图,效果很(hěn)不错。
限界上下文(wén)(Bounded Context)和数据耦合
除了多(duō)领域join的问题,我们在业務(wù)中还会经常碰到一些场景,比如電(diàn)商(shāng)中的商(shāng)品信息是基础信息,属于单独的BC,而其他(tā)BC,不管是营销服務(wù)、价格服務(wù)、購(gòu)物(wù)車(chē)服務(wù)、订单服務(wù)都是需要引用(yòng)这个商(shāng)品信息的。但是需要的商(shāng)品信息只是全部的一小(xiǎo)部分(fēn)而已,营销服務(wù)需要商(shāng)品的id和名称、上下架状态;订单服務(wù)需要商(shāng)品id、名称、目录、价格等等。这比起商(shāng)品中心定义一个商(shāng)品(商(shāng)品id、名称、规格、规格值、详情等等)只是一个很(hěn)小(xiǎo)的子集。这说明不同的限界上下文(wén)的同样的术语,但是所指的概念不一样。 这样的问题映射到我们的实现中,每次在订单、营销模块中直接查询商(shāng)品模块,肯定是不合适,因為(wèi):
商(shāng)品中心需要适配每个服務(wù)需要的数据,提供不同的接口
并发量必然很(hěn)大
服務(wù)之间的耦合严重,一旦宕机、升级影响的范围很(hěn)大
特别是最后一条,严重限制了我们获得微服務(wù)提供的优势“松耦合、每个服務(wù)自己可(kě)以频繁升级不影响其他(tā)模块”。这就需要我们通过事件驱动方法,适当冗余一些数据到不同的BC去,把这种耦合拆解开。这种耦合有(yǒu)时候是通过Value Object嵌入到实體(tǐ)中的方式,在生成实體(tǐ)的时候就冗余,比如订单在生成的时候就冗余了商(shāng)品的信息;有(yǒu)时候是通过额外的Value Object列表方式,营销中心冗余一部分(fēn)相关的商(shāng)品列表数据,并随时关注监听商(shāng)品的上下级状态,同步替换掉本限界上下文(wén)的商(shāng)品列表。
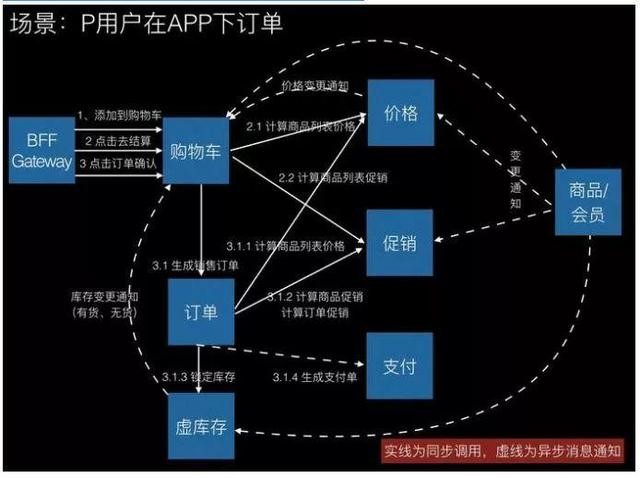
下图一个下单场景分(fēn)析,在電(diàn)商(shāng)系统中,我们可(kě)以认為(wèi)会员和商(shāng)品是所有(yǒu)业務(wù)的基础数据,他(tā)们的变更应该是通过广播的方式发布到各个领域,每个领域保留自己需要的信息。
保证最终一致性
最终一致性成功依赖很(hěn)多(duō)条件
1. 依赖消息传递的可(kě)靠性,可(kě)能(néng)A系统变更了状态,消息发到B系统的时候丢失了,导致AB的状态不一致。
2. 依赖服務(wù)的可(kě)靠性,如果A系统变更了自己的状态,但是还没来得及发送消息就挂了,也会导致状态不一致。
我记得JavaEE规范中的JMS中有(yǒu)针对这两种问题的处理(lǐ)要求,一个是JMS通过各种确认消息(Client Acknowledge等)来保证消息的投递可(kě)靠性,另外是JMS的消息投递操作可(kě)以加入到数据库的事務(wù)中-即没有(yǒu)发送消息,会引起数据库的回滚(没有(yǒu)查资料,不是很(hěn)准确的描述,请专家指正)。不过现在符合JMS规范的MQ没几个,特别是保一致性需要降低性能(néng),现在标榜高吞吐量的MQ都把问题抛给了我们自己的应用(yòng)解决。所以这里介绍几个常见的方法,来提升最终一致性的效果。
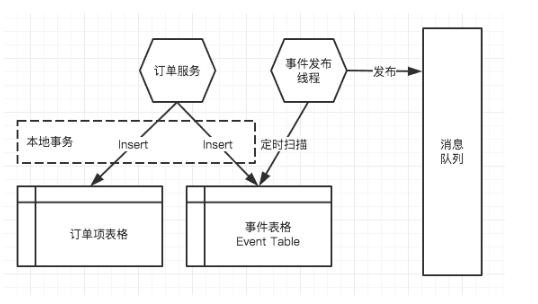
使用(yòng)本地事務(wù)
还是以上面的订单扣取信用(yòng)的例子:
订单服務(wù)开启本地事務(wù),首先新(xīn)增订单;
然后将Order Created事件插入一张专门Event表,事務(wù)提交;
有(yǒu)一个单独的定时任務(wù)線(xiàn)程,定期扫描Event表,扫出来需要发送的就丢到MQ,同时把Event设置為(wèi)“已发送”。
方案的优势是:
使用(yòng)了本地数据库的事務(wù),如果Event没有(yǒu)插入成功,那么订单也不会被创建;線(xiàn)程扫描后把event置為(wèi)已发送,也确保了消息不会被漏发(我们的目标是宁可(kě)重发,也不要漏发,因為(wèi)Event处理(lǐ)会被设计為(wèi)幂等)。
缺点是:
需要单独处理(lǐ)Event发布在业務(wù)逻辑中,繁琐容易忘记;Event发送有(yǒu)些滞后;定时扫描性能(néng)消耗大,而且会产生数据库高水位隐患;我们稍作改进,使用(yòng)数据库特有(yǒu)的MySQL Binlog跟踪(阿里的Canal)或者Oracle的GoldenGate技术可(kě)以获得数据库的Event表的变更通知,这样就可(kě)以避免通过定时任務(wù)来扫描了。
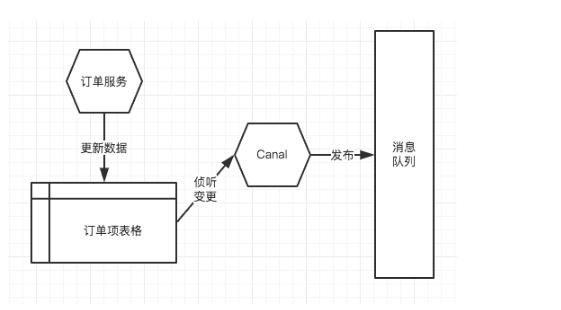
不过用(yòng)了这些数据库日志(zhì)的工具,会和具體(tǐ)的数据库实现(甚至是特定的版本)绑定,决策的时候请慎重。
使用(yòng)Event Sourcing 事件溯源
事件溯源对我们来说是一个特别的思路,他(tā)并不持久化Entity对象,而是只把初始状态和每次变更的Event记录下来,并在内存中根据Event还原Entity对象的最新(xīn)状态,具體(tǐ)实现很(hěn)类似数据库的Redolog的实现,只是他(tā)把这种机制放到了应用(yòng)层来。
虽然事件溯源有(yǒu)很(hěn)多(duō)宣称的优势,引入这种技术要特别小(xiǎo)心,首先他(tā)不一定适合大部分(fēn)的业務(wù)场景,一旦变更很(hěn)多(duō)的情况下,效率的确是个大问题;另外一些查询的问题也是困扰。
我们仅仅在个别的业務(wù)上探索性的使用(yòng)Event Souring和AxonFramework,由于实现起来比较复杂,具體(tǐ)的情况还需要等到实践一段时间后再来总结,也许需要额外的一篇文(wén)章来详细描述。