
- 行业动态 >
- 资讯详情
数据管理(lǐ)的未来发展趋势
 2019/08/27
2019/08/27
 2038
文(wén)章来源:软件定义世界(SDX)
2038
文(wén)章来源:软件定义世界(SDX)



当前,数据驱动型业務(wù)战略与信息产品的潜力比以往任何时候都要大。对于多(duō)数企业机构而言,数据分(fēn)析与管理(lǐ)已成為(wèi)它们业務(wù)战略的重要驱动力。数据分(fēn)析与管理(lǐ)领导者正在通过挖掘数据价值来驱动数字化转型、创造盈利机会、改善客户體(tǐ)验和重塑行业格局。
随着云、本地、边缘间的界限逐渐消失,数据管理(lǐ)的未来可(kě)以用(yòng)四个关键词来描述。

首先是分(fēn)布式(Distributed),未来的数据管理(lǐ)将是分(fēn)布式的,因為(wèi)数据管理(lǐ)须随数据所在的位置而进行。
其次是无服務(wù)器(Serverless),此概念较特殊、并不是指未来的数据管理(lǐ)不再需要服務(wù)器,而是指未来将没有(yǒu)一个明确的集中式服務(wù)器。
再者是协调(Orchestrated),今天的数据会产生在不同的地方和设备上,所以须把它们协调管理(lǐ)。
最后就是元数据(Metadata),无论数据分(fēn)散在何处,元数据均能(néng)把它们协调在一起,因此元数据是未来数据管理(lǐ)中非常重要的一个元素。

总體(tǐ)而言,数据管理(lǐ)的未来发展趋势可(kě)从三个维度来看——架构的改变、技术的转变以及组织的衍化。

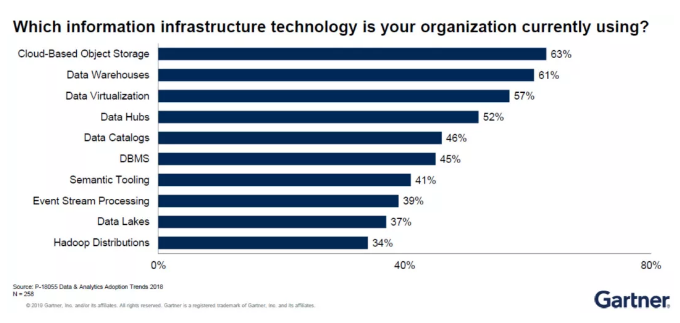
Gartner于2018年针对数据和分(fēn)析的采用(yòng)趋势进行了一项调查(多(duō)选题)。结果显示企业机构目前使用(yòng)最普遍的信息基础架构技术為(wèi)“基于云平台的数据存储”(63%)。
一些传统技术,例如数据仓库(Data Warehouse)和数据库管理(lǐ)系统(DBMS)仍然占着相当大的比重。这些传统技术在未来并不会消失。
举例而言,“数据仓库”是一个非常广泛的案例,未来数据的研究和分(fēn)析都将需要用(yòng)到该技术——主要配合在特定案例和场合中使用(yòng)。
此外,未来还将有(yǒu)诸如“数据目录”(Data Catalogs)这样的技术被广泛使用(yòng)。
“数据目录”是元数据的重要基础,以往“数据目录”主要用(yòng)于帮助企业机构了解数据的定义和来源,但现在的趋势是“数据目录”可(kě)以帮助企业机构了解数据的特性、使用(yòng)者以及使用(yòng)场景。
因此,在数据管理(lǐ)的未来趋势中,“数据目录”将具有(yǒu)举足轻重的地位。
此外,数据湖(hú)(Date Lake)已从此前放置在内部数据中心中转变為(wèi)目前可(kě)放在云端上,这是一个非常大的变化,未来诸如此类比较高端的技术均可(kě)以移至云平台之上。
1) 重“关联”、轻“采集”
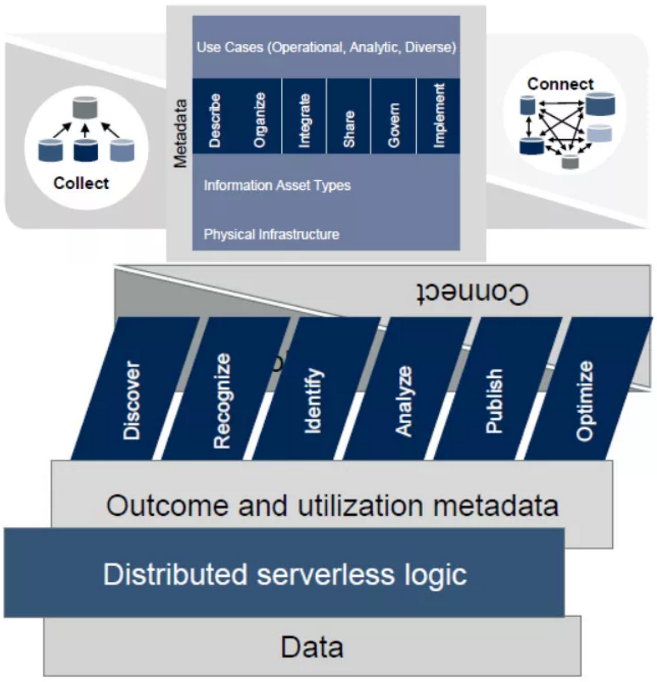
从上述调查背景可(kě)以看出,未来的数据管理(lǐ)和集成将会变得更加“关联”(Connect),更少“采集”(Collect)。
当前,在数据管理(lǐ)上,企业机构通常重“采集”、轻“关联”,此情形在中國(guó)尤為(wèi)严重——即企业机构在采集和存储数据后,并不能(néng)立即挖掘其中的价值,失去其时效性。
原因在于,从数据被“采集”到应用(yòng)其价值,这中间有(yǒu)相当長(cháng)的流程(如上左图所示),包括描述、整理(lǐ)、集成、分(fēn)享、治理(lǐ)和实施。这一長(cháng)串流程对企业机构内部IT技术具有(yǒu)相当大的考验。
随着机器學(xué)习技术的引入和元数据的应用(yòng),目前数据管理(lǐ)和集成已开始呈现出一种新(xīn)趋势,即更加注重数据的“关联”(如上右图所示),也就是指无论数据是在本地、云端、某个设备感应器上或任何地方,我们都可(kě)以在数据保留在原地的情况下,将它们关联起来,而无须采集到特定地方。
在未来增强式的数据管理(lǐ)的环境中,自动发掘数据、透过机器自动意识识别数据中的价值、认定有(yǒu)价值的数据、分(fēn)析数据、自动采用(yòng)适合数据的安全措施、分(fēn)享数据、优化数据,最终实现在最短时间内将精准的数据发送给对的人,对于企业机构至关重要。
1) “移动性数据”成為(wèi)主要案例
数据管理(lǐ)与集成方面的另一个趋势是“移动性数据”(Data in Motion)。
以往,诸如交易产生后,企业机构便把数据存储进数据库或数据中心内,后续任務(wù)即制作报表等工作,这类的数据被称為(wèi)“静态型”。
“移动性数据”指的是在交易过程中,企业机构就可(kě)以看到实时的数据处理(lǐ)——无论数据处在边缘设备还是在数据中心内。数据始终是数据商(shāng)用(yòng)平台的核心所在。
2) 集中式、分(fēn)布式、随机式数据治理(lǐ)并存
与数据管理(lǐ)(Data Management)不同,数据治理(lǐ)(Data Governance)注重数据的使用(yòng)者、使用(yòng)方式、使用(yòng)权限的合规性制定。
未来的“数据治理(lǐ)”将会非常动态——可(kě)以是集中式、分(fēn)布式,亦可(kě)是随机式。“随机式”是指企业机构可(kě)以通过机器學(xué)习来增强数据内容以及评估用(yòng)例。
举例而言,某件物(wù)品在首次被海关征收关税时,海关可(kě)能(néng)不知如何“治理(lǐ)”它。但“机器學(xué)习”引擎可(kě)以自动分(fēn)辨该物(wù)品的属性,进而据此自动帮助海关生成此件物(wù)品应该遵循的“治理(lǐ)”规则。
3) 元数据是未来数据管理(lǐ)的关键
企业机构的数据来源不仅多(duō)种多(duō)样(包括ERP、CRM、SCM和HCM),且用(yòng)途极為(wèi)广泛(可(kě)用(yòng)于外部供应商(shāng)、客户与合作伙伴,呈现方式包括图表、报表和指示板)。
将这些来源与用(yòng)途连接起来——即连通无服務(wù)器进程(Serverless Processes)和物(wù)理(lǐ)合并(Physical Consolidation)的关键桥梁就是元数据。
Gartner预计,在2021年之前,能(néng)够采用(yòng)数据中心、数据湖(hú)或者数据仓库这种统一战略的企业机构,将比竞争对手多(duō)出30%的使用(yòng)案例。
此外,在2023年之前,75%的数据库将迁移至云平台上,此举意味着减少数据库管理(lǐ)系统供应商(shāng)的规模并且增加数据治理(lǐ)和集成的复杂性。
1)人工智能(néng)让数据管理(lǐ)软件的运行更加流畅

现在,人工智能(néng)可(kě)以帮助企业机构增强数据管理(lǐ)。事实上,数据管理(lǐ)技术的未来就是人工智能(néng)和机器學(xué)习的应用(yòng)。
具體(tǐ)而言,有(yǒu)以下四方面:
第一是数据质量(Data Quality)。目前市场上有(yǒu)很(hěn)多(duō)供应商(shāng)都是在用(yòng)机器學(xué)习的方式帮助企业机构扩展和增强数据的分(fēn)析、清理(lǐ)、连接、识别、语义协调和重组。企业机构在不同数据源中管理(lǐ)主数据质量以往需要人為(wèi)操作、费时费力,而机器學(xué)习可(kě)以使这一整串流程变得完全自动化,且准确率明显提高。
第二是主数据管理(lǐ)(Master Data Management)。机器學(xué)习可(kě)以帮助企业机构配置和优化主数据,尤其在记录匹配和算法融合方面,机器學(xué)习可(kě)以让企业机构对主数据的管理(lǐ)更加便利。
第三是数据集成(Data Integration)。人工智能(néng)可(kě)以通过升级多(duō)个相同模式并根据语义分(fēn)析,向企业机构告知数据源的相关性,推荐企业机构将相同的数据源进行连接,最终使得数据集成的流程更加简化。
第四是数据库管理(lǐ)系统(DataBase Management System)。人工智能(néng)技术的引入将使数据库从存储、索引、分(fēn)區(qū)到调整、优化、修补——这一系列繁琐的人工流程变得更加自动化。
2)动态元数据创造“自我驱动型”数据管理(lǐ)
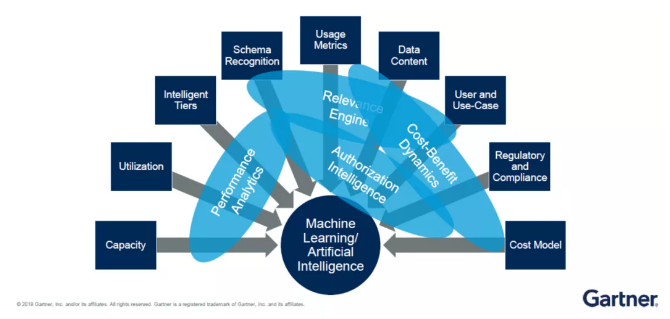
机器學(xué)习和人工智能(néng)是一个后端底层技术,诸如性能(néng)分(fēn)析等更多(duō)数据管理(lǐ)工作的完成还需动态元数据的支持。元数据专门用(yòng)于描述数据的特质,帮助企业机构将不同的数据进行关联并做推荐。
以数据分(fēn)析為(wèi)例,企业机构在定义数据的相关性时,动态元数据就会起到中间凝合力的作用(yòng)。
3)开源软件收益与风险的平衡
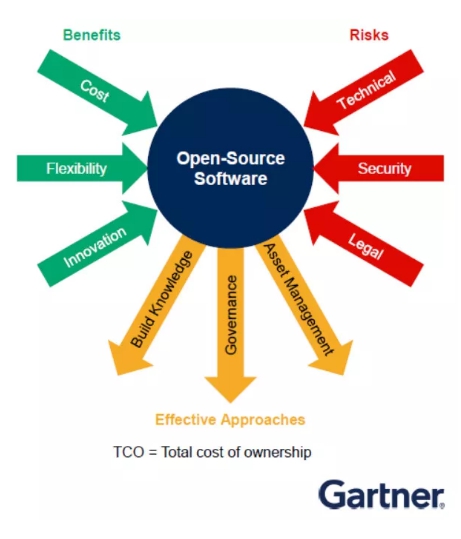
提及开源,一般想到的是总拥有(yǒu)成本(TCO)很(hěn)低、企业机构的回本速度很(hěn)快。
虽然企业机构有(yǒu)时无法通过开源软件(OSS)得到所需支持,但目前市场上已有(yǒu)很(hěn)多(duō)商(shāng)业软件包可(kě)给予帮助。
其次,若企业机构需要研发创新(xīn)并保持灵活性,那么开源软件应是首要选择。
再者,据Gartner调查,全球90%的企业机构已把开源软件用(yòng)在任務(wù)关键型的IT流程中。
最后,企业机构应把服務(wù)水平协议与商(shāng)业供应商(shāng)的平衡性放入自身的数据管理(lǐ)策略考量中。

Gartner预测,到2022年之前,使用(yòng)动态元数据去连接、优化、自动化数据集成流程的企业机构将减少30%的数据交付的时间。
此外,到2023年之前,在数据管理(lǐ)中使用(yòng)人工智能(néng)技术能(néng)够帮助企业机构进行更多(duō)的自动化工作,因此这些企业机构对于IT专业人士的需求将减少20%。
1)自动化数据与分(fēn)析工作即将来临
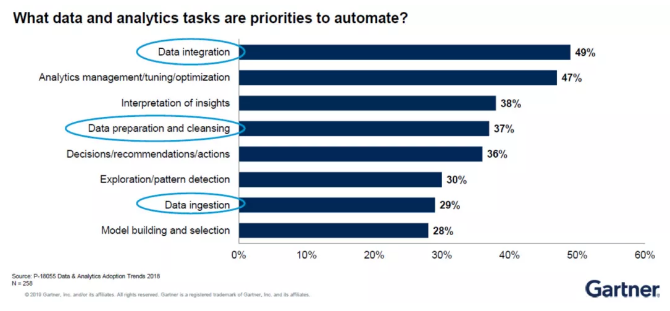
Gartner就数据分(fēn)析工作的自动化优先级进行过一项调研。调研结果显示,数据集成(Data Integration)排名第一,因為(wèi)其最费时间也最易出错。
此外,机器學(xué)习相关技术的研发需要进行大量前期的数据准备(Data Preparation)。Gartner预计数据科(kē)學(xué)家大约需要花(huā)费70%到80%的时间进行数据准备。
因此,若数据准备无法进行自动化,那么项目交付的时间就会极其漫長(cháng)。
2)人机联盟:少花(huā)钱、多(duō)做事
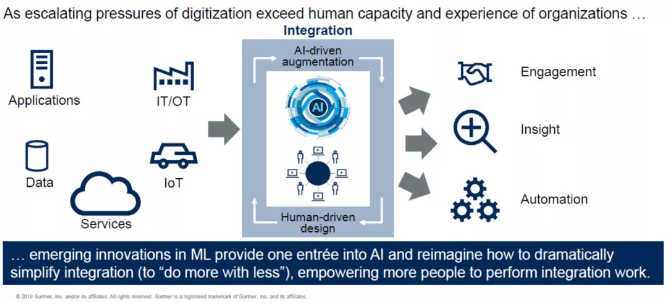
未来,数据集成工作需要人与机器共同完成。数据存在不同的端口且数量庞大,因此单独的人力难以进行处理(lǐ)、需有(yǒu)工具进行支持。未来,这种工具将引入人工智能(néng)与机器學(xué)习技术,让人力做不到或短期内无法实现的工作变成现实。
与此同时,此前从事这类工作的IT工程师将可(kě)腾出时间去做更多(duō)、更重要的事情。
3)元数据与数据管理(lǐ)架构紧密贴合
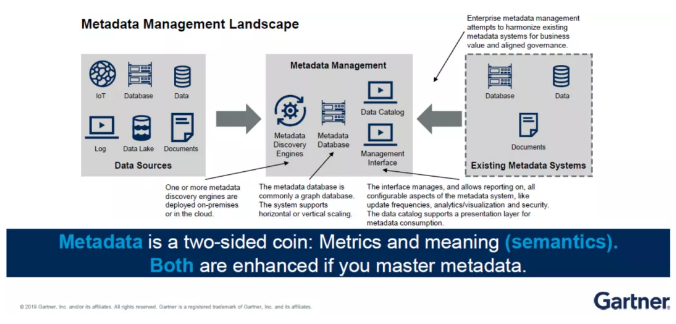
元数据的管理(lǐ)平台上有(yǒu)很(hěn)多(duō)引擎,有(yǒu)些可(kě)以根据数据目录,即目前所存储的数据信息,自动地发现企业机构目前架构中有(yǒu)哪些数据源还未掌控,然后进行处理(lǐ)。
元数据有(yǒu)两种维度——度量(Metrics)与语义(Meaning)。
以往,企业机构做得更多(duō)的是语义,但在未来元数据的管理(lǐ)上,两者具有(yǒu)同等重要性,甚至“度量”的地位更高,因為(wèi)它可(kě)以根据此前类似数据的集成方式自动进行数据挖掘和规划。
4)数据管理(lǐ)新(xīn)角色不断涌现
Gartner针对“企业机构目前及2020前的数据管理(lǐ)职位”进行过调研,结果如上图所示。其中,需重点强调的是数据管家(Data Steward)。“数据管家”在未来的数据管理(lǐ)工作中占有(yǒu)极其重要的地位。
当前,企业机构已经意识到自己的数据源变得更多(duō)、数据使用(yòng)案例变得更為(wèi)复杂,在此情况下,它们需要新(xīn)的岗位去应对挑战。
但需强调的是,每个企业机构都有(yǒu)自己不同的战略,它们需要根据预测的业務(wù)结果来应用(yòng)不同的技能(néng)、设置不同的数据管理(lǐ)岗位。