
- 行业动态 >
- 资讯详情
simhash与重复信息识别
 2019/07/29
2019/07/29
 24225
文(wén)章来源:CSDN 原作者:grunt1223
24225
文(wén)章来源:CSDN 原作者:grunt1223



事实上,传统比较两个文(wén)本相似性的方法,大多(duō)是将文(wén)本分(fēn)词之后,转化為(wèi)特征向量距离的度量,比如常见的欧氏距离、海明距离或者余弦角度等等。两两比较固然能(néng)很(hěn)好地适应,但这种方法的一个最大的缺点就是,无法将其扩展到海量数据。例如,试想像Google那种收录了数以几十亿互联网信息的大型搜索引擎,每天都会通过爬虫的方式為(wèi)自己的索引库新(xīn)增的数百万网页,如果待收录每一条数据都去和网页库里面的每条记录算一下余弦角度,其计算量是相当恐怖的。
我们考虑采用(yòng)為(wèi)每一个web文(wén)档通过hash的方式生成一个指(fingerprint)。传统的加密式hash,比如md5,其设计的目的是為(wèi)了让整个分(fēn)布尽可(kě)能(néng)地均匀,输入内容哪怕只有(yǒu)轻微变化,hash就会发生很(hěn)大地变化。我们理(lǐ)想当中的哈希函数,需要对几乎相同的输入内容,产生相同或者相近的hashcode,换句话说,hashcode的相似程度要能(néng)直接反映输入内容的相似程度。很(hěn)明显,前面所说的md5等传统hash无法满足我们的需求。
simhash是localitysensitivehash(局部敏感哈希)的一种,最早由MosesCharikar在《similarityestimationtechniquesfromroundingalgorithms》一文(wén)中提出。Google就是基于此算法实现网页文(wén)件查重的。我们假设有(yǒu)以下三段文(wén)本:
thecatsatonthemat
thecatsatonamat
weallscreamforicecream
使用(yòng)传统hash可(kě)能(néng)会产生如下的结果:
irb(main):006:0>p1='thecatsatonthemat'
irb(main):005:0>p2='thecatsatonamat'
irb(main):007:0>p3='weallscreamforicecream'
irb(main):007:0>p1.hash=>415542861
irb(main):007:0>p2.hash=>668720516
irb(main):007:0>p3.hash=>767429688
使用(yòng)simhash会应该产生类似如下的结果:
irb(main):003:0>p1.simhash=>85145919800110010110000000011110001111110
irb(main):004:0>p2.simhash=>84726386400110010100000000011100001111000
irb(main):002:0>p3.simhash=>98496808800111010101101010110101110011000
海明距离的定义,為(wèi)两个二进制串中不同位的数量。上述三个文(wén)本的simhash结果,其两两之间的海明距离為(wèi)(p1,p2)=4,(p1,p3)=16以及(p2,p3)=12。事实上,这正好符合文(wén)本之间的相似度,p1和p2间的相似度要遠(yuǎn)大于与p3的。
如何实现这种hash算法呢(ne)?以上述三个文(wén)本為(wèi)例,整个过程可(kě)以分(fēn)為(wèi)以下六步:
1、选择simhash的位数,请综合考虑存储成本以及数据集的大小(xiǎo),比如说32位
2、将simhash的各位初始化為(wèi)0
3、提取原始文(wén)本中的特征,一般采用(yòng)各种分(fēn)词的方式。比如对于"thecatsatonthemat",采用(yòng)两两分(fēn)词的方式得到如下结果:
{"th","he","e","c","ca","at","t","s","sa","o","on","n","t","m","ma"}
4、使用(yòng)传统的32位hash函数计算各个word的hashcode,比如:"th".hash=-502157718,"he".hash=-369049682,……
5、对各word的hashcode的每一位,如果该位為(wèi)1,则simhash相应位的值加1;否则减1
6、对最后得到的32位的simhash,如果该位大于1,则设為(wèi)1;否则设為(wèi)0
整个过程可(kě)以参考下图:
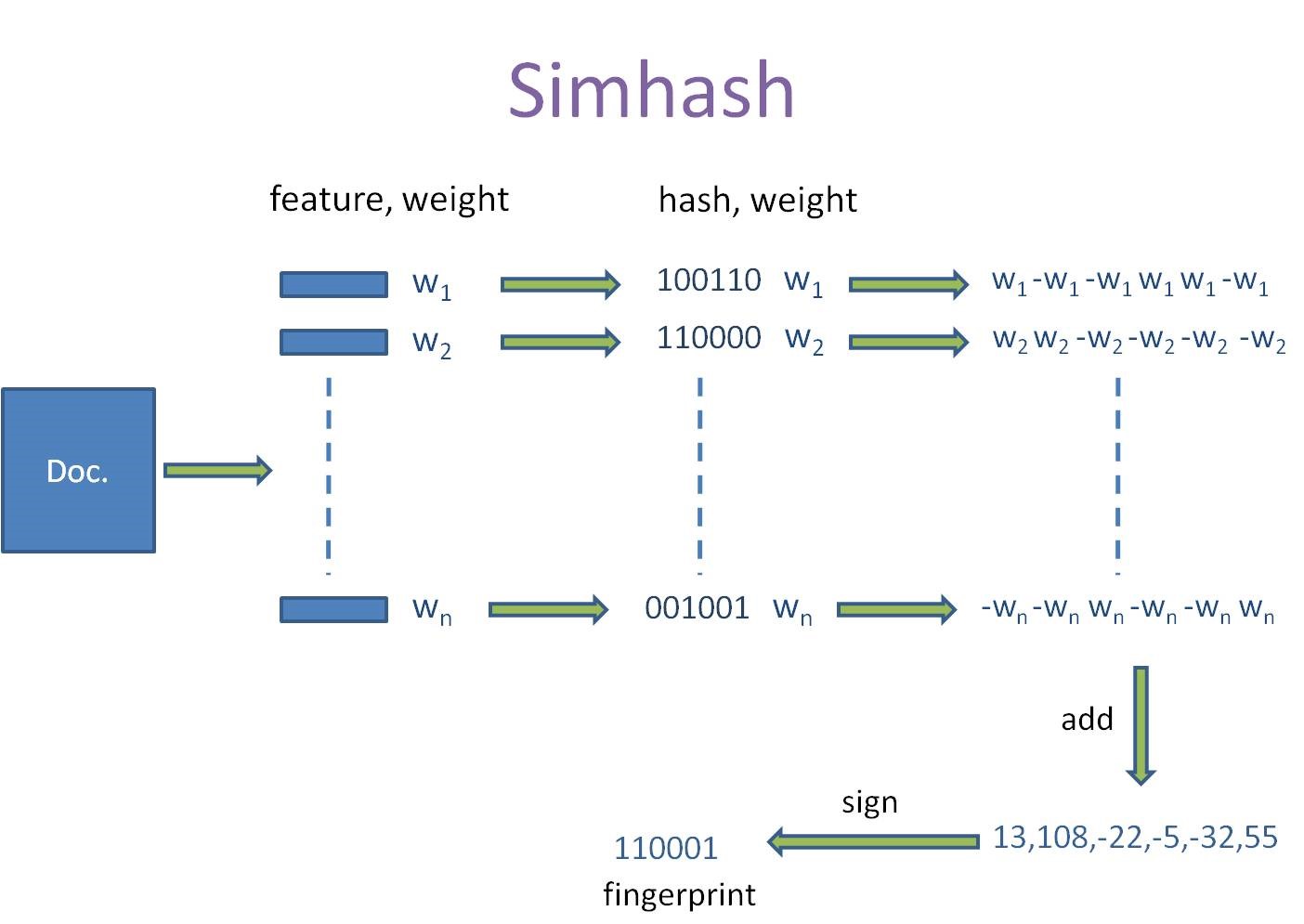
按照Charikar在论文(wén)中阐述的,64位simhash,海明距离在3以内的文(wén)本都可(kě)以认為(wèi)是近重复文(wén)本。当然,具體(tǐ)数值需要结合具體(tǐ)业務(wù)以及经验值来确定。
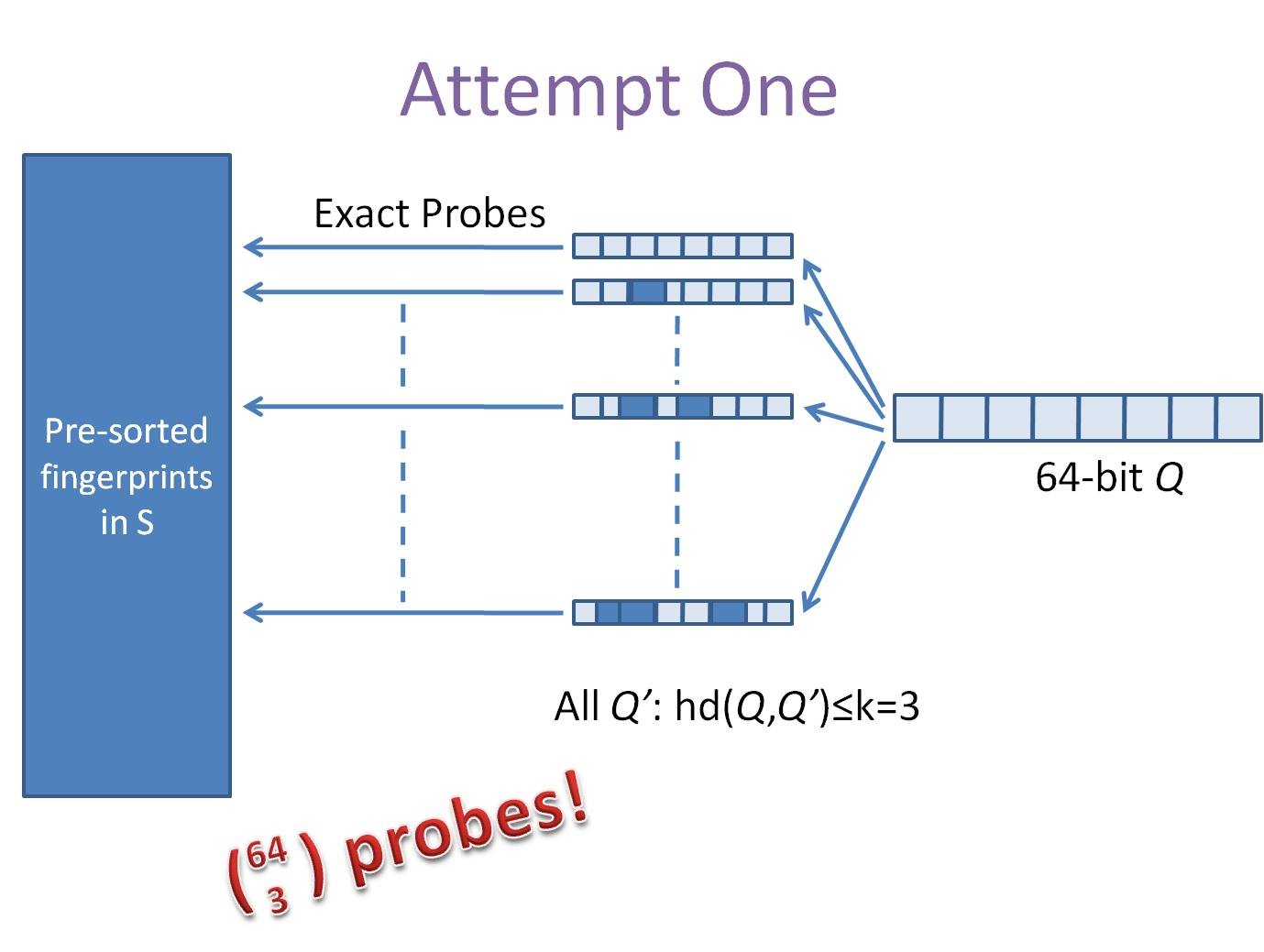
使用(yòng)上述方法产生的simhash可(kě)以用(yòng)来比较两个文(wén)本之间的相似度。问题是,如何将其扩展到海量数据的近重复检测中去呢(ne)?譬如说对于64位的待查询文(wén)本的simhashcode来说,如何在海量的样本库(>1M)中查询与其海明距离在3以内的记录呢(ne)?下面在引入simhash的索引结构之前,先提供两种常规的思路。第一种是方案是查找待查询文(wén)本的64位simhashcode的所有(yǒu)3位以内变化的组合,大约需要四万多(duō)次的查询,参考下图:
另一种方案是预生成库中所有(yǒu)样本simhashcode的3位变化以内的组合,大约需要占据4万多(duō)倍的原始空间,参考下图:
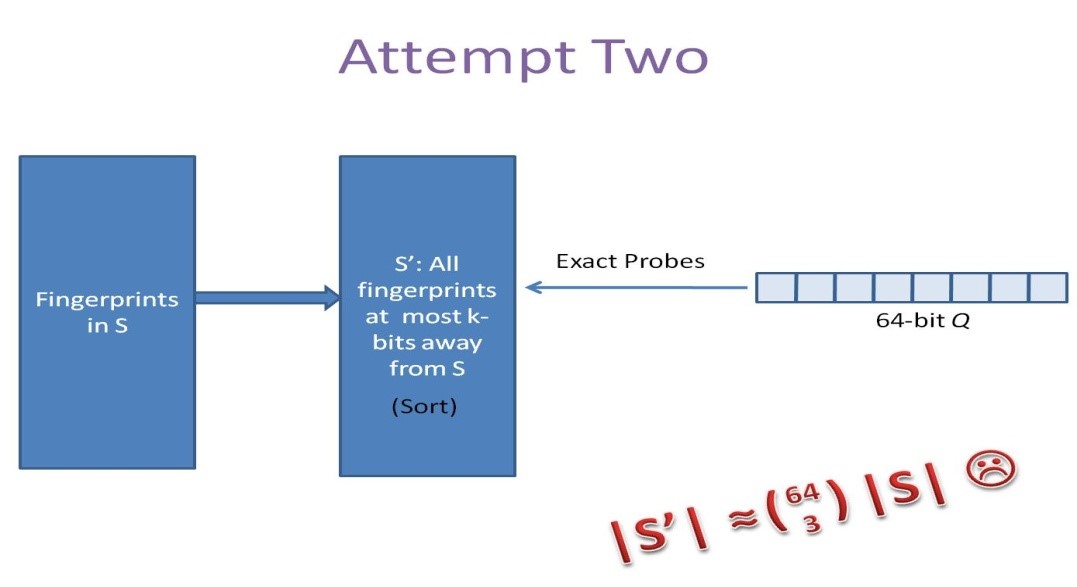
显然,上述两种方法,或者时间复杂度,或者空间复杂度,其一无法满足实际的需求。我们需要一种方法,其时间复杂度优于前者,空间复杂度优于后者。
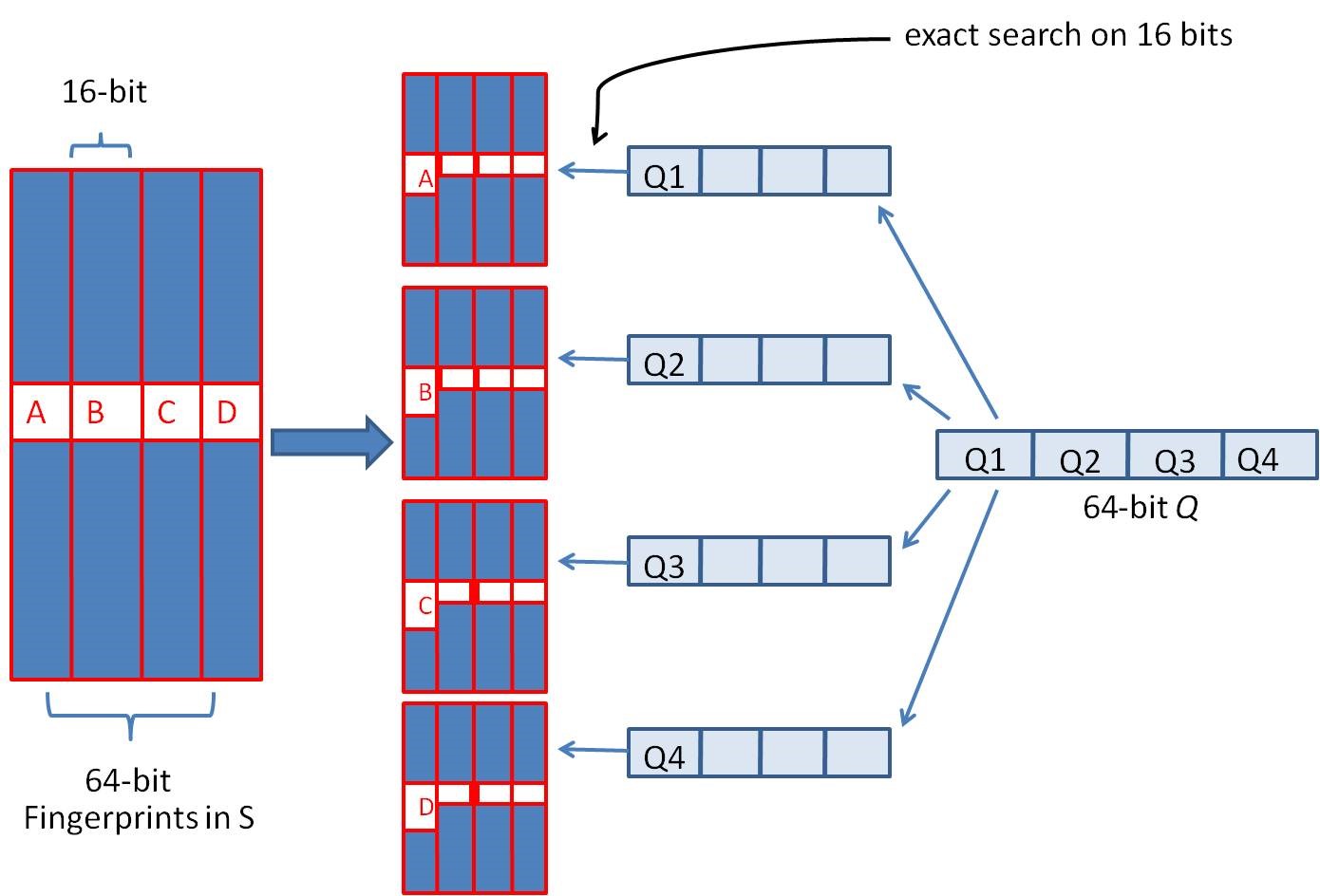
假设我们要寻找海明距离3以内的数值,根据抽屉原理(lǐ),只要我们将整个64位的二进制串划分(fēn)為(wèi)4块,无论如何,匹配的两个simhashcode之间至少有(yǒu)一块區(qū)域是完全相同的,如下图所示:
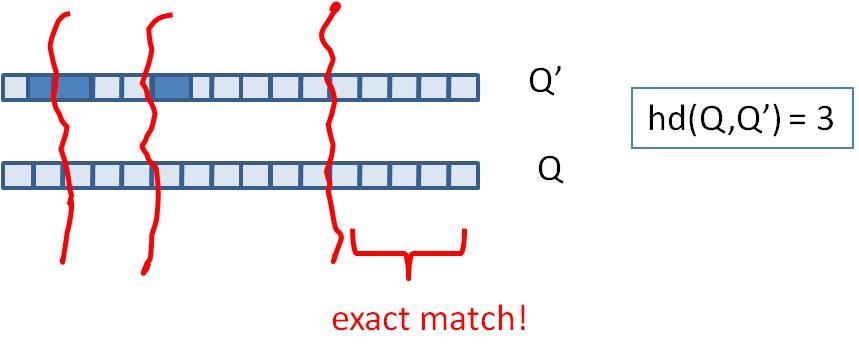
由于我们无法事先得知完全相同的是哪一块區(qū)域,因此我们必须采用(yòng)存储多(duō)份table的方式。在本例的情况下,我们需要存储4份table,并将64位的simhashcode等分(fēn)成4份;对于每一个输入的code,我们通过精确匹配的方式,查找前16位相同的记录作為(wèi)候选记录,如下图所示:
让我们来总结一下上述算法的实质:
1、将64位的二进制串等分(fēn)成四块
2、调整上述64位二进制,将任意一块作為(wèi)前16位,总共有(yǒu)四种组合,生成四份table
3、采用(yòng)精确匹配的方式查找前16位
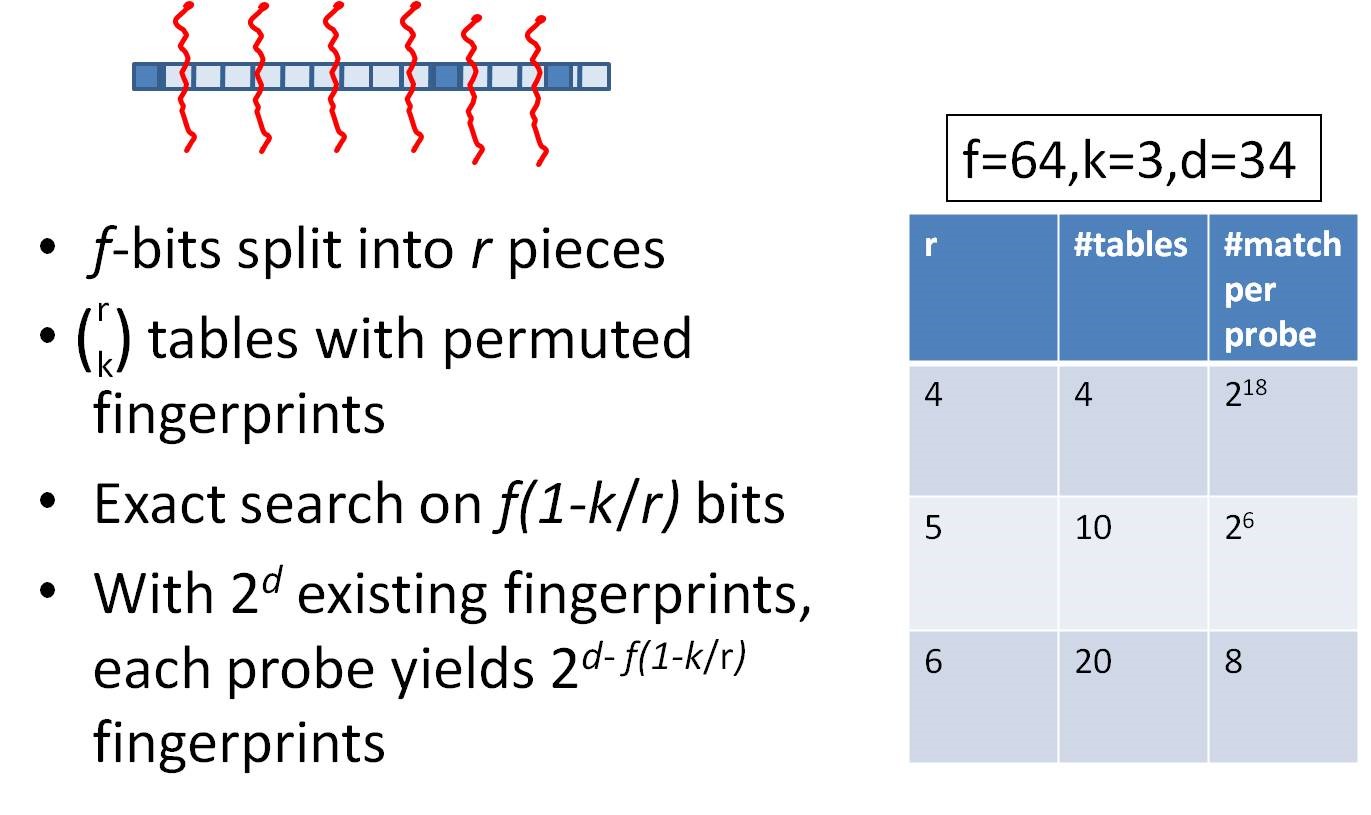
4、如果样本库中存有(yǒu)2^34(差不多(duō)10亿)的哈希指纹,则每个table返回2^(34-16)=262144个候选结果,大大减少了海明距离的计算成本
我们可(kě)以将这种方法拓展成多(duō)种配置,不过,请记住,table的数量与每个table返回的结果呈此消彼長(cháng)的关系,也就是说,时间效率与空间效率不可(kě)兼得,参看下图:
事实上,这就是Google每天所做的,用(yòng)来识别获取的网页是否与它庞大的、数以十亿计的网页库是否重复。另外,simhash还可(kě)以用(yòng)于信息聚类、文(wén)件压缩等。
也许,读到这里,你已经感受到数學(xué)的魅力了。