
- 行业动态 >
- 资讯详情
基于Docker的京东大数据实时计算平台
 2017/03/29
2017/03/29
 2337
文(wén)章来源:
2337
文(wén)章来源:




JRC用(yòng)户需求多(duō)样复杂,用(yòng)户要求的资源配置也大小(xiǎo)不一,系统更新(xīn)部署步骤繁琐,人工操作亦有(yǒu)极大的安全风险,与此同时,用(yòng)户的资源需求也越来越多(duō),大集群支持、资源节省亦是我们应该重点关注的问题。
本文(wén)就来介绍一种我们京东為(wèi)了解决上述问题而研发的基于docker的实时计算平台。
现状以及问题
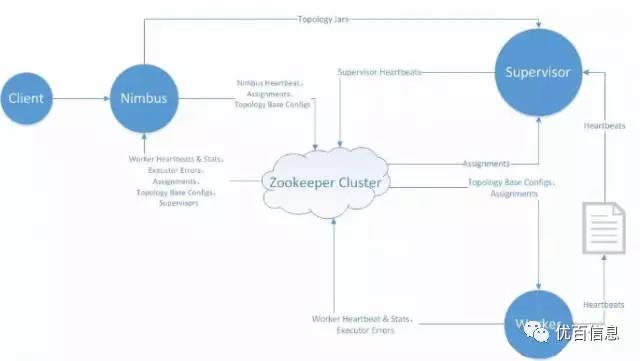
storm集群结构:
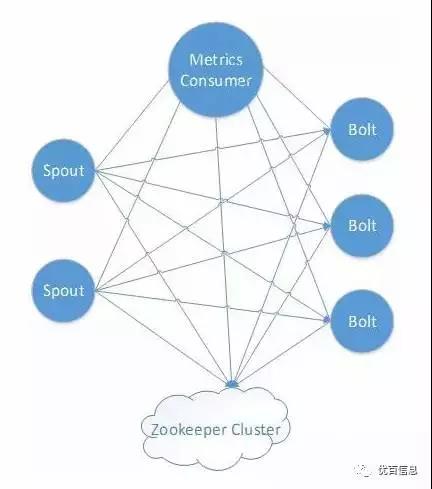
storm拓扑结构:
storm瓶颈
从storm架构图可(kě)以看出,storm整个集群对zookeeper的依赖非常大,无论是拓扑配置、分(fēn)配信息、心跳、错误信息,均存储在zookeeper中,而nimbus每次分(fēn)配、更新(xīn)任務(wù),均需要从zookeeper中获取这些信息,因此nimbus的压力非常大,特别是当单集群worker使用(yòng)量超过5000时,每次分(fēn)配、更新(xīn)任務(wù)所耗的时间经常需要几分(fēn)钟,其中特别是worker心跳对zookeeper所造成的压力影响最甚。
众所周知,京东业務(wù)广泛,对实时计算的需求也很(hěn)大,对应所要求的集群规模也不可(kě)能(néng)小(xiǎo),因此京东对于上述这些问题也必须做出改变以适应自身业務(wù)的发展,其中最大的改变即是对拓扑应用(yòng)结构的改变,增设了TopologyMaster角色,把metrics、心跳、背压等信息均由TopologyMaster处理(lǐ),大大减轻了nimbus及zookeeper压力,当然啦,还有(yǒu)很(hěn)多(duō)很(hěn)多(duō)很(hěn)不错的改动,但这不是本文(wén)的重点,就不在此累赘了。改变后的拓扑结构為(wèi)
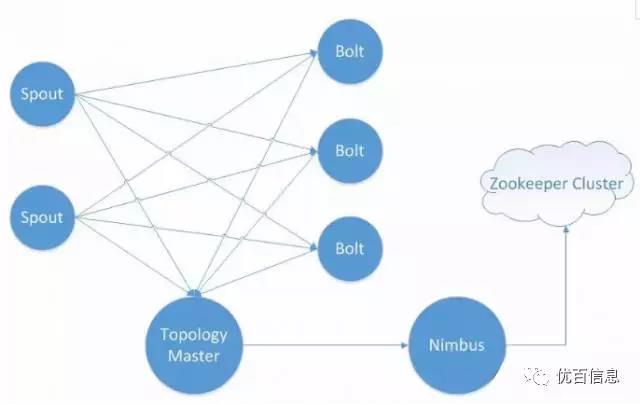
為(wèi)响应京东集群资源上云号召,京东实时计算平台虽然解决了大集群、资源隔离等用(yòng)户或集群所面临的重要问题,但若直接把整个storm照搬上弹性云平台虚拟机使用(yòng),则无法满足资源隔离需求,届时,集群用(yòng)户任務(wù)之间的相互影响很(hěn)可(kě)能(néng)带来各种不可(kě)预见的问题,因此我们必需对storm底层进行一次完整的改造。
技术架构实现
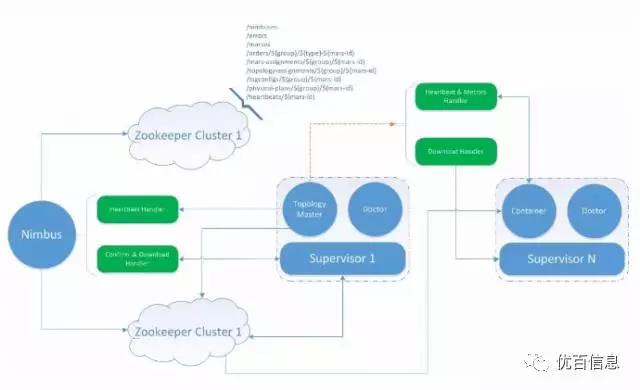
如图所示,我们将Storm的Nimbus功能(néng)进行拆分(fēn),将拓扑的主要管理(lǐ)职能(néng)交给TopologyMaster,改造后的storm在我们内部称之為(wèi)Mars,意寓发现新(xīn)大陆。
Mars主要有(yǒu)以下几个特性。
1.二级调度
改造后的Nimbus只需管理(lǐ)TopologyMaster的调度,其它如UI访问、命令下发、拓扑更新(xīn)、分(fēn)配、背压、metrics、心跳等,均由TopologyMaster负责处理(lǐ),真正实现了完整意义上的二级调度。
2.资源隔离
改造后每个docker实例下只有(yǒu)一个supervisor,并且每个supervisor里只用(yòng)一个worker,通过每个docker一个worker来进行worker级别的资源隔离。此外,我们引入了组的概念,不用(yòng)用(yòng)户申请的资源也可(kě)以统一放到一个组上,一个任務(wù)只能(néng)运行在一个组内,并通过产品化来引入权限管理(lǐ),以此保证不同用(yòng)户申请的资源不会被他(tā)人占用(yòng)。
3.全高可(kě)用(yòng)(High Availability)
基础进程HA
我们在每个docker实例里内置一个管理(lǐ)进程mars admin,并配置crontab每分(fēn)钟检测mars admin进程状态,保证mars admin发生异常后自动重启。Mars admin管理(lǐ)着supervisor进程、进行日志(zhì)服務(wù)的doctor进程、抓取日志(zhì)的bee进程,这些进程的启停与更新(xīn)由mars admin来执行,保障每个docker实例里的基础进程的HA。
Nimbus HA
我们通过Zookeeper来实现Active-Standby模式的nimbus ha,由于改造后nimbus的工作内容很(hěn)少,因此单机执行完全足够满足需求。
TopologyMaster HA
TopologyMaster会定期与Nimbus进行心跳交互,若Nimbus检测到TM心跳超时,则会重新(xīn)调起一个新(xīn)的TM,新(xīn)的TM会将自身信息写入Zookeeper中,其它Container与Supervisor将通过Zookeeper来识别到新(xīn)的TM,从而保障TM的HA。
Container/Worker HA
Container会定期与TM进行交互,若TM检测到Container心跳超时,则会重新(xīn)从资源池里调起一个新(xīn)的Container接管原来失效Container的任務(wù),并把新(xīn)的任務(wù)分(fēn)配写入Zookeeper中,以便其它Container识别新(xīn)的Container的位置,从而保障Container的HA。
4.自动部署
由于一个docker一个worker,而一个docker实例可(kě)以理(lǐ)解為(wèi)一个虚拟机,用(yòng)户资源申请具有(yǒu)随机性、配置个性化等特点,因此对我们配置管理(lǐ)上必需具有(yǒu)自适应性。对此我们通过提供一个特殊镜像,通过产品化把JRC与云平台资源申请打通,并把资源配置、包部署等功能(néng)产品化,以达到自动部署的目的。
总结
基于docker的实时计算平台是京东自行研发的全新(xīn)的、自动化的实时计算平台,它基于storm理(lǐ)念,通过重新(xīn)设计整个底层架构及运行逻辑,并添加背压、压缩、限速、监控、日志(zhì)等辅助功能(néng),经过产品化并与弹性云平台打通,达到了用(yòng)户申请即可(kě)用(yòng)、配置个性化、大规模集群的要求,操作高效且自动化。