
- 优百发布 >
- 资讯详情
不忘初心方得始终,数据质量管理(lǐ)要稳住!
 2020/03/05
2020/03/05
 2102
文(wén)章来源:CSDN 作者:蒋珍波
2102
文(wén)章来源:CSDN 作者:蒋珍波



一、数据质量管理(lǐ)的目标
数据质量管理(lǐ)主要解决「数据质量现状如何,谁来改进,如何提高,怎样考核」的问题。
為(wèi)什么这篇文(wén)章的标题中有(yǒu)“不忘初心方得始终”这几个字呢(ne)。因為(wèi)最开始的关系型数据库时代,做数据治理(lǐ)最主要的目的,就是為(wèi)了提升数据质量,让报表、分(fēn)析、应用(yòng)更加准确。时至今日,虽然数据治理(lǐ)的范畴扩大了很(hěn)多(duō),我们开始讲数据资产管理(lǐ)、知识图谱、自动化的数据治理(lǐ)等等概念,但是提升数据的质量,依然是数据治理(lǐ)最重要的目标之一。
為(wèi)什么数据质量问题如此重要?
因為(wèi)数据要能(néng)发挥其价值,关键在于其数据的质量的高低,高质量的数据是一切数据应用(yòng)的基础。
如果一个组织根据劣质的数据分(fēn)析业務(wù)、进行决策,那还不如没有(yǒu)数据,因為(wèi)通过错误的数据分(fēn)析出的结果往往会带来“精确的误导”,对于任何组织来说,这种“精确误导”都无异于一场灾难。

根据统计,数据科(kē)學(xué)家和数据分(fēn)析员每天有(yǒu)30%的时间浪费在了辨别数据是否是“坏数据”上,在数据质量不高的环境下,做数据分(fēn)析可(kě)谓是战战兢兢。可(kě)见数据质量问题已经严重影响了组织业務(wù)的正常运营。通过科(kē)學(xué)的数据质量管理(lǐ),持续地提升数据质量,已经成為(wèi)组织内刻不容缓的优先任務(wù)。
二、数据质量问题从何而来?
做数据质量管理(lǐ),首先要搞清楚数据质量问题产生的原因。原因有(yǒu)多(duō)方面,比如在技术、管理(lǐ)、流程方面都会碰到。但从根本上来时,数据质量问题产生的大部分(fēn)原因在于业務(wù)上,也就是管理(lǐ)不善。许多(duō)表面上的技术问题,深究下去,其实还是业務(wù)问题。

我在给客户做数据治理(lǐ)咨询的时候,发现很(hěn)多(duō)客户认识不到数据质量问题产生的根本原因,局限于只想从技术角度来解决问题,希望通过購(gòu)买某个工具就能(néng)解决质量问题,这当然达不到理(lǐ)想的效果。经过和客户交流以及双方共同分(fēn)析之后,大部分(fēn)组织都能(néng)认识到数据质量问题产生的真正根源,从而开始从业務(wù)着手解决数据质量问题了。
从业務(wù)角度着手解决数据质量问题,重要的是建立一套科(kē)學(xué)、可(kě)行的数据质量评估标准和管理(lǐ)流程。
三、数据质量评估的标准
当我们谈到数据质量管理(lǐ)的时候,我们必须要有(yǒu)一个数据质量评估的标准,有(yǒu)了这个标准,我们才能(néng)知道如何评估数据的质量,才能(néng)把数据质量量化,并知道改进的方向,比较改进后的效果。
目前业内认可(kě)的数据质量的标准有(yǒu):
准确性: 描述数据是否与其对应的客观实體(tǐ)的特征相一致。
完整性: 描述数据是否存在缺失记录或缺失字段。
一致性: 描述同一实體(tǐ)的同一属性的值在不同的系统是否一致
有(yǒu)效性: 描述数据是否满足用(yòng)户定义的条件或在一定的域值范围内。
唯一性: 描述数据是否存在重复记录。
及时性: 描述数据的产生和供应是否及时。
稳定性: 描述数据的波动是否是稳定的,是否在其有(yǒu)效范围内。
以上数据质量标准只是一些通用(yòng)的规则,这些标准是可(kě)以根据数据的实际情况和业務(wù)要求进行扩展的,如交叉表校验等。
四、数据质量管理(lǐ)流程
要提升数据质量,需要以问题数据為(wèi)切入点,注重问题的分(fēn)析、解决、跟踪、持续优化、知识积累,形成数据质量持续提升的闭环。
首先需要梳理(lǐ)和分(fēn)析数据质量问题,摸清楚数据质量的现状;然后针对不同的质量问题选择适合的解决办法,制定出详细的解决方案;接着是问题的认责,追踪方案执行的效果,监督检查,持续优化;最后形成数据质量问题解决的知识库,以供后来者参考。上述步骤不断迭代,形成数据质量管理(lǐ)的闭环。
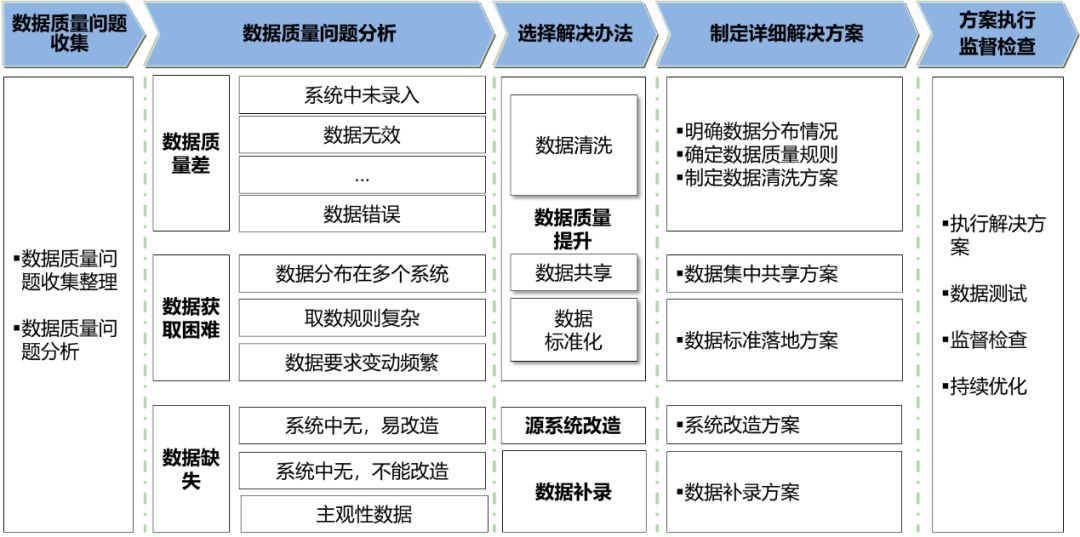
很(hěn)显然,要管理(lǐ)好数据质量,仅有(yǒu)工具支撑是遠(yuǎn)遠(yuǎn)不够的,必须要组织架构、制度流程参与进来,做到数据的认责,数据的追责。这和我在第一篇文(wén)章《数据治理(lǐ):那些年,我们一起踩过的坑》中阐述的观点是一致的,大家可(kě)以参考那篇文(wén)章。
五、数据质量管理(lǐ)的取与舍
企业也好,政府也好,从来不是生活在真空之中,而是被社会紧紧地包裹。解决任何棘手的问题,都必须考虑到社会因素的影响,做适当的取舍。
第一个取舍:数据质量管理(lǐ)流程。前面讲到的数据质量管理(lǐ)流程,是一个相对理(lǐ)想的状态,但是不同的组织内部,其实施的力度都是不同的,以数据追责為(wèi)例:在企业内部推行还具有(yǒu)一定的可(kě)行性,但是在政府就很(hěn)难适用(yòng)。因為(wèi)政府部门的大数据项目,牵头单位无论是谁,很(hěn)可(kě)能(néng)没有(yǒu)相关的权限。举个例子:你很(hěn)难想像市经信委去跟市政府办公厅进行数据质量的问责。这与数据治理(lǐ)的建设方在整个大的组织體(tǐ)系中的话语权有(yǒu)很(hěn)大的关系。这就是我们做数据治理(lǐ)必须接受的现实。遇到这种问题,我们只能(néng)迂回地做些事情,尽量弥补某个环节缺失带来的不利影响,比如和数据提供方一起建立起数据清洗的规则,对来源数据做清洗,尽量达到可(kě)用(yòng)的标准。
第二个取舍:不同时间维度上的数据采取不同的处理(lǐ)方式。从时间维度上划分(fēn),数据主要有(yǒu)三类:未来数据、当前数据、历史数据。在解决不同种类的数据质量问题时,需要考虑取舍之道,采取不同的处理(lǐ)方式。